Summary:
To build useful and usable AI-powered systems, our understanding of users’ needs and our design judgement must be encoded into well-defined evaluation criteria.
Design Decisions in Generative AI Systems
Imagine asking a large language model a question like “How’s the weather today?” The response might include too much information (“it’s 72 degrees, and it feels like 72 degrees with wind chill”) or too little (“It’s nice out!”). It might say “It’s unlikely to rain” when there’s a 30% chance — technically below 50%, but high enough that most people would want to know. The AI is making design decisions about what to include in the response and how to phrase it. Without being able to specify every possible design decision the model might make, how do we influence these design decisions to be the “right” ones — the ones that serve users’ needs best, as grounded in research and our understanding of our target users?
The Shift from Deterministic to Probabilistic Systems
To answer this question, we can consider how design specifications are traditionally used when developing systems that are not AI-powered. Basically, our expectation as designers is that our engineering and QA partners will read our specs and write code that implements the exact behaviors we specify, including tests that validate that the code behaves as expected by the spec. Tools like Figma have simplified this process by allowing us to generate certain types of UI code and tests automatically, but this is the core model.
The reason that we can specify exact behaviors lies in the deterministic nature of non-AI-powered software applications. When deterministic code is run with the same inputs, it always produces the same outputs. AI models, by contrast, are nondeterministic: even when they are given the same inputs, no two outputs are guaranteed to be the same. This is the source of the AI’s flexibility, but it also means that we cannot expect adherence to an exact specification.
Designers Must Define What Good Looks Like
This is where design critique comes in. If we reframe our task as designers from specifying exact behaviors to defining what “good” looks (and doesn’t look) like, we can create mechanisms by which our engineering and data-science partners can evaluate how closely the model’s behavior adheres to our intentions. The definition of “good” still comes from user research and design expertise: observed behaviors, articulated needs, and patterns of frustration, as interpreted through a design lens; we are simply expressing it differently.
While the examples below are drawn from my own experience in designing conversational systems, I believe this approach can be generalized to designing for any system powered primarily by generative AI.
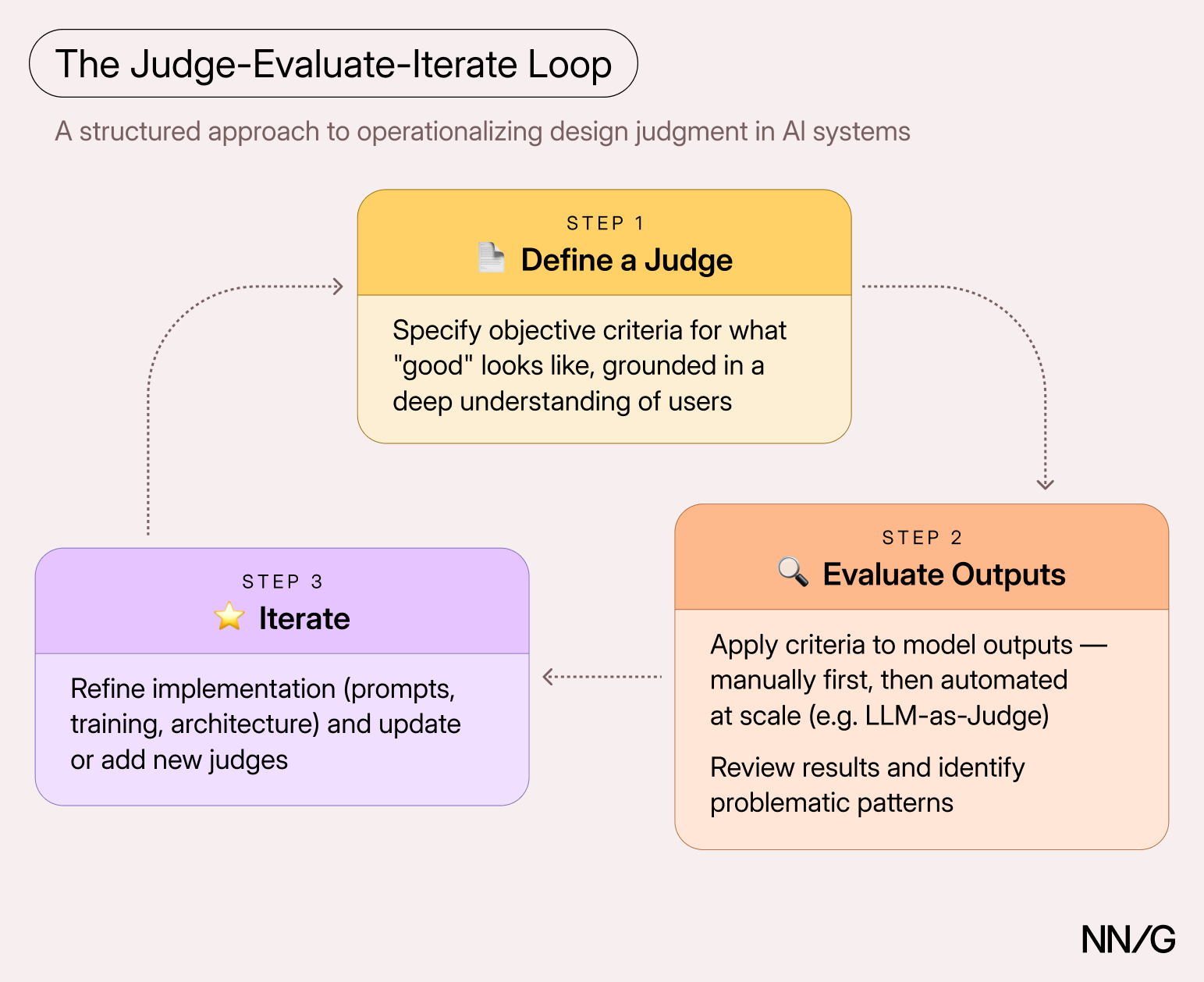
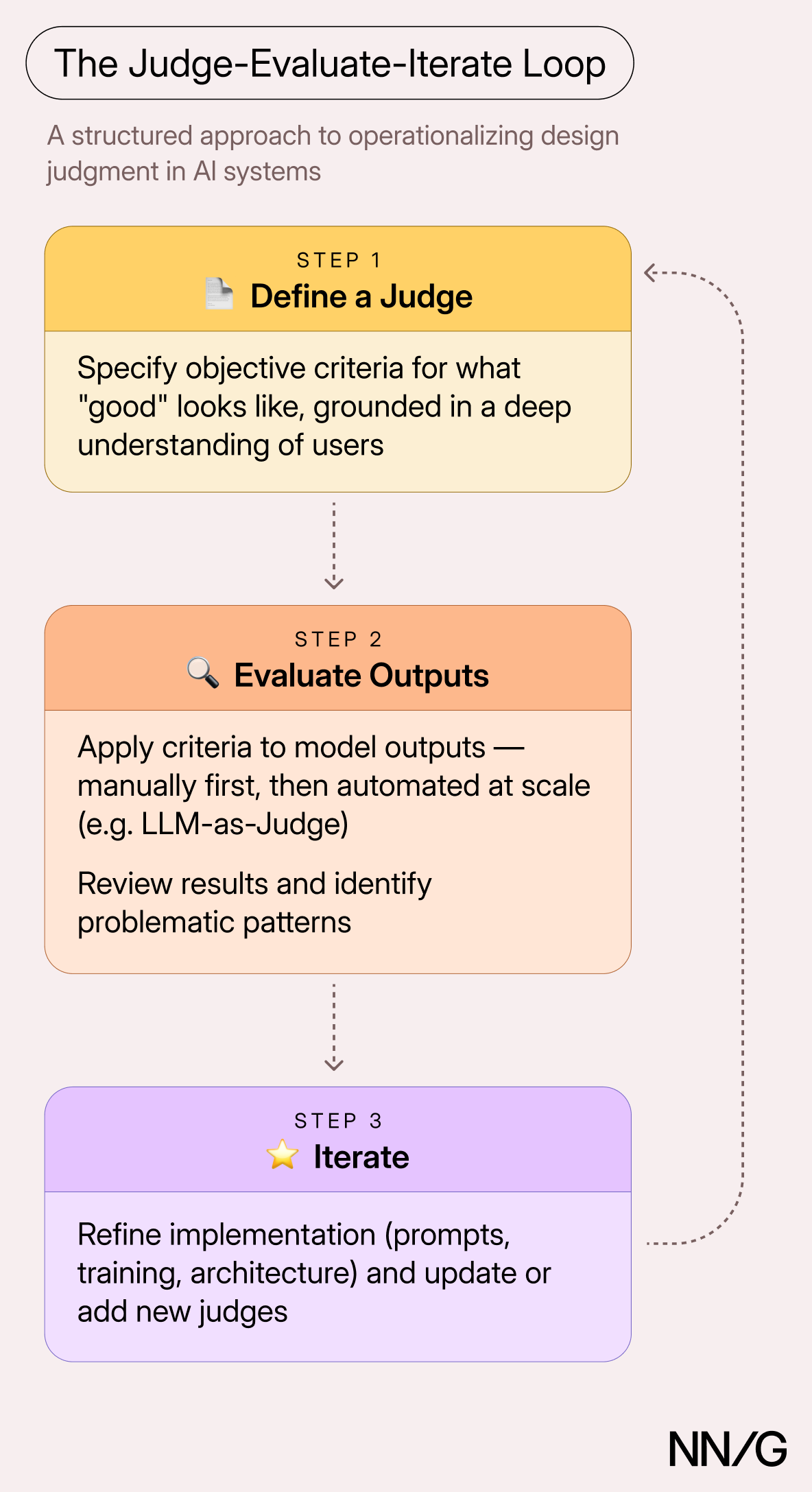
Judge-Evaluate-Iterate
In my own practice as a conversation designer, we implemented a judge-evaluate-iterate loop. We start by defining judge criteria for evaluating whether the system’s output meets our definition of “good.” We then use those criteria to evaluate the actual output. Finally, we use the results of the evaluation to identify improvement areas and work with our data-science and engineering partners to refine the implementation. In addition, as we identify new patterns of undesirable behavior, we use those to define additional judging criteria, restarting the loop.
One caveat: while this process works well for conversational experiences, it may be harder to apply it to visually oriented experiences. Recording system inputs and outputs to “replay” them against evaluation models is relatively straightforward when both are text, but it isn’t clear yet how to represent graphical inputs and outputs in an evaluation dataset. Even so, AI models are clearly capable of interpreting visual inputs as well as text or speech, and we expect evaluation capabilities to evolve through advances of tools like accessibility scanners and design-system linters.
1. Defining a Judge
The first step in this process is to define a set of judging criteria that can be used to evaluate a specific model output and determine whether it is acceptable. These criteria are where designers can exercise the most authorship. Ultimately, they will serve as an expression of our understanding of how the system should use context and resources to service our intended customer needs and use cases.
The most critical aspect of creating judging criteria is to make them as objective as possible — but not arbitrary. Some criteria are inherently objective; for example, whether specific information appears in the response is easy to evaluate and will produce highly consistent judgments across different judges (human or AI). Other criteria are more difficult to define objectively. In designing for voice conversations, for example, we often care about response verbosity — that is, how long the response is. This is challenging to evaluate objectively. Years of research and user observations show that “overly verbose” varies based on the situation and the user, so an arbitrary threshold (e.g.,, “response must be less than 10 seconds”) won’t work. A 5-second response might be considered too long for a simple request to turn off a light, while a 20-second response might be too short for a complex, open-ended question.
However, asking evaluators whether an output “feels overly verbose” also won’t work, because different individuals (and AI models) will have their own ideas of what “feels verbose.” Vague criteria force the evaluator to exercise design judgement, which is subjective.
I addressed this problem with a two-step approach. First, I specified criteria to classify responses into various types; I then created different evaluation criteria for each response type. For example, a response to an open-ended question might pass if it “fully answered the question and included at most one or two additional pieces of highly relevant information.” While this criterion still has some subjectivity (evaluators might disagree slightly on what “fully answered” and “highly relevant” mean), it is objective enough to ensure that most evaluators would agree on most responses. That level of consistency is especially critical when using automated evaluation tools (see below).
2. Evaluating Model Outputs
Once the judging criteria are defined, they are applied against the model’s actual output.. At first, this may be a manual process — humans interact with the system, record its outputs, and annotate whether those outputs meet the judging criteria.
To scale, however, this process can be automated. User inputs can be collected and “replayed” against updated models, prompts, and system architectures to generate new results for evaluation. AI models can also be prompted to simulate user behavior in “using” the system, although this practice is generally considered riskier since AI behaviors will differ widely from actual user behavior.
On the evaluation side, the judging criteria can be turned into prompts for a separate AI model to act as a judge on the output. This pattern, called “LLM as a judge,” can align reasonably well with human evaluators’ judgments when the judge is carefully calibrated against human annotations. A good measure of the evaluation quality is the F1 score — the average of precision and recall when an LLM-annotated dataset is compared against human annotations. We have found that an LLM judge that can achieve an F1 score of 0.8 is reliable enough for generating useful evaluation results.
3. Iterating Implementations and Judges
I’ve found several ways to use evaluation results to improve implementation. I usually start by reviewing example outputs that are considered failures by various judges (generally prioritizing the ones with lower “passing” rates). Those examples tend to reveal two patterns: 1) behaviors that seem to cause actual failed responses; and 2) behaviors that don’t actually seem to be failures.
The former can be used to identify areas of improvement for prompt engineering; the latter can help determine how to update the judge criteria.
I’ve also seen that it’s possible to feed the evaluation criteria and failure cases themselves as inputs to an LLM, with a request to optimize the prompt to provide better results. This approach often works better than prompt trial and error and allows for more rapid iteration.
Sometimes, I’ve found models resistant to prompt engineering.. In those cases, I’ve had success creating pairs of “good” and “bad” responses to the same prompt. To do this, I take a relatively small set of “failing” responses and rewrite them to pass our criteria. Those response pairs can then be used to finetune the model and nudge it in the right direction.
|
Conversation |
Judge Score & Rationale |
|
|---|---|---|
|
Bad Example |
U: Add Tommy’s birthday to my calendar. |
FAIL: Repeats the system’s willingness to do the task twice, and repeats the phrase “Tommy’s birthday” twice as well. |
|
Good Example |
U: Add Tommy’s birthday to my calendar. |
PASS: –Repeats “Tommy’s birthday” once, just enough to confirm that the system heard the user properly. |
Best Practices for Implementing the Judge-Evaluate-Iterate Loop
Of course, there are a number of challenges in implementing this process. Here are some of the best practices I’ve found.
Calibrate All LLM/AI Judges and Verify All LLM/AI Outputs
Models are highly capable of producing convincing outputs that are completely made-up and unsupported. LLMs make automated evaluations fast and scalable, but if those evaluations aren’t carefully calibrated against a representative, human-annotated test set , that data may be completely useless and may degrade performance as easily as it can improve it. The same is true for LLM-generated test data or prompt optimizations — without human review (at least, on a sample), they are unlikely to lead to success.
Break Down Complex Evaluation Criteria into Components
Evaluation criteria can often be broken down into multiple judges. For example, in the verbosity case above, we first classified the conversation type and then evaluated verbosity. This practice can also simplify evaluations (and thus make them faster and cheaper), as those components may require less powerful models or could even be handled with deterministic rules. For example, if a criterion for a visual UX is “adheres to our visual-style guide,” it might make sense to have separate judges for requirements like appropriate typefaces, type sizes, brand colors, or color contrast that meet WCAG standards.
Watch for Regressions
In deterministic systems, once a bug is fixed, it generally stays fixed unless a related piece of code is changed. With AI, chaos theory seems to apply: prompt changes or training-data updates that seem completely unrelated to the criteria you care about may still cause issues. It’s important to keep evaluating across all the criteria you care about as models and prompts change, even if you have been seeing positive results for a long time.
Conclusion
Those of us designing conversational experiences are on the bleeding edge of working this way, but the shift from static, predefined experiences to AI-powered dynamic ones will soon impact every user experience. To meet this moment and deliver high-quality experiences, we need to embrace our role as the arbiters of “good design” — not simply as a matter of taste, but as a matter of considered judgement and solid design critique. That critique must be grounded in a deep understanding of users and a rigorous definition of what “good” looks like.