Learning the fundamentals of the World Wide Web is crucial, especially if you are planning to build web apps. And, HTTP is at the heart of any web application you could build.
HTTP stands for Hypertext Transfer Protocol. It’s a stateless, application-layer protocol for communicating between distributed systems, and is the foundation of the modern web.
In this article, I’ll start with the basics. I’ll explain the aspects of HTTP that any potential web developer should know. Then we’ll dive into the deeper, and advanced theories of HTTP.
HTTP is a Hypertext Transfer Protocol
When you open a web site in a browser, you see text, images and embedded content. All this content is loaded from servers elsewhere on the web. It is the role of the browser—also called a client—to raise a request for this content. The request is sent to a server, which in return sends a response back to the browser. Both the request, and the response are sent as human-readable text.
Every request raised by the browser is independent. The HTTP protocol is stateless. That means that each individual request needs to carry all the information needed to fulfill it. In a HTTP request, this information is passed through headers.
The HTTP protocol supports a mix of network configurations. The browser is one of the many possible clients which can raise a request. The requests are sent, and responses are received over the TCP/IP layer. The default port for HTTP communication is port 80, but this can be configured differently for different applications.
HTTP Versions
- Currently, clients use version HTTP/2.0. Recent releases of Chrome, Firefox, Safari, and Edge all support HTTP/2.0. This version of HTTP allows the client to send multiple requests simultaneously. This technique is known as multiplexing. It cuts down on the time required to load a page.
- HTTP/1.1 was revised in the year 2014. This version allows only a single outstanding request with every TCP/IP connection. This mechanism is also known as baseline.
- HTTP/0.9 was the original version of the protocol. Currently, this version is completely deprecated.
The flow diagram, below, explains why HTTP/2.0 is better than HTTP/1.1.
As seen, HTTP/2.0 allows the client to request for both the style, and script simultaneously. Likewise, the style, and script gets loaded at the same time. The entire process gets completed in a single TCP connection.
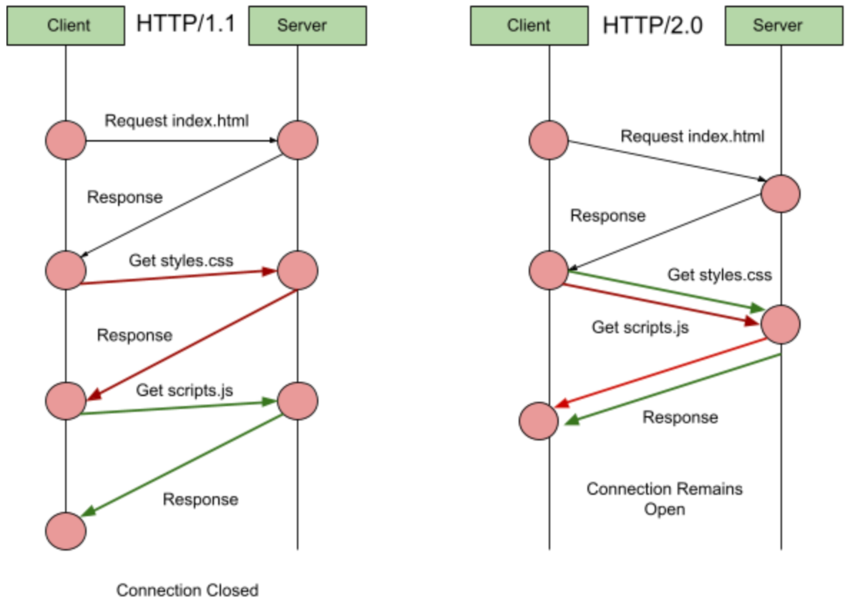
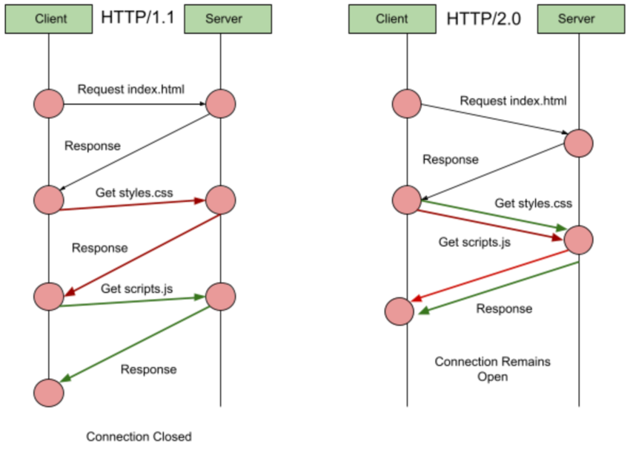
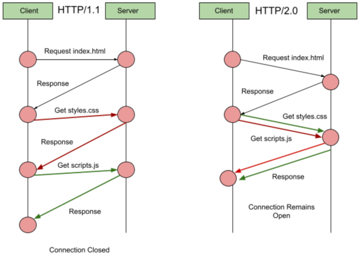
Also, HTTP/2.0 comes with smart packet management strategies, and header compression mechanisms to cut down on latency.
HTTP URLs
Requests are sent to servers specified with Uniform Resource Locators (URLs). I’m sure you are already familiar with URLs, but for completeness sake, I’ll include it here. URLs have a simple structure that consists of the following components:
https://www.domain.com:1234/path/to/resource?a=b&x=y
- https specifies the protocol. It can be http or https, which makes the communication secure.
-
www.domain.com
is the host.
- 1234 is the port. In many cases, the browser hides the port. The default is 80.
- path/to/resource is the resource path. It helps the server identify a specific resource, and generate the right response.
- ?a=b&x=y are query string parameters. Query string parameters is used by the server to spot the right resource.
The URL identifies the specific host with which the client wants to communicate. It does not perform any action. This is where the request comes. HTTP has a formalized way of framing requests that capture all the required pieces of information, which can be applied by any kind of application.
HTTP Requests
At the heart of web communications is the request message. A request is made up of the following parts:
- request line: this says what is being requested. Consists of a verb, a path, and the HTTP version. The HTTP verb says what action is requested of the host, eg. to GET a resource or POST form data.
- headers: additional information about the message, the requester and the communication format.
- body (optional): the content of the request. For a simple request for a static resource like a web page, this will be empty. For a form submission, this will contain the information from the form. The body is separated from the headers by a blank line.
Here’s a typical HTTP request:
GET /articles/http-basics HTTP/1.1 Host: www.articles.com Connection: keep-alive Cache-Control: no-cache Pragma: no-cache Accept: text/html, application/xhtml+xml, application/xml;q=0.9, */*;q=0.8
The first line has the verb, resource path and HTTP version. In this case, we are trying to GET the resource at /articles/http-basics. The rest of the request lines are headers—this request has no body.
HTTP Request Verbs
There are four universally applicable HTTP verbs in a Request:
- GET: fetch a resource from the server. For a GET request, the URL should carry all the required pieces of information for the server to spot the right resource. It does not have a message body.
- POST: create a new resource. The request has optional payload which helps the server create a new resource.
- PUT: update an existing resource. The request should have an optional payload to help the server update an existing resource.
- DELETE: delete an existing resource.
The above four verbs are the most popular ones. Interestingly, PUT and DELETE are sometimes considered as specialised versions of the POST verb. In certain cases, PUT may be packaged as a POST request with the payload containing the exact action: create, update or delete.
There are some less-used verbs to. A few to consider are:
- HEAD is similar to GET, but without the message body. It’s used to retrieve the server headers for a particular resource, generally to check if the resource has changed, via timestamps.
-
TRACE is used to retrieve the hops that a request takes during a round trip from the server. Each intermediate proxy or gateway would inject its IP or DNS name into the
Viaheader field. This can be used for diagnostic purposes. - OPTIONS is used to retrieve server capabilities. In the client-side, it can be used to modify the request based on what the server supports.
HTTP Headers
HTTP headers give the server information about the sender, the way the client wants to interact and the message. Each header is a name-value pair. The HTTP Protocol specifies all the valid HTTP headers the client and server can use.
A bunch of general headers are shared by both the request, and response messages:
-
Cache-Control: a directive that controls how caching happens in CDNs, proxies or browsers. It became effective from HTTP/1.1. -
Connection: used to decide if the network connection needs to be closed or open, once a request is completed. Possible values arekeep-alive, orclosed. -
Pragmais an interesting and heavily implementation-specific header. It is provided only for backwards compatibility with HTTP/1.0, which does not supportCache-Control. -
Trailer: tells the server it can append metadata to the message body, for example an integrity check or digital signature. -
Transfer-encoding: defines the encoding of the payload transferred from the server. Often, this is known as the hop by hop header because the encoding is applied between nodes, and not between the server and client. -
Viais used in the header to track messages, and the capabilities of the client or server. -
Upgradeis available only in HTTP/1.1 and above. If the client or server is allowed to shift from one protocol to another, this header has to be set. For example:Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11.
Here are some of the headers that are specific to the request:
-
Accept-prefixed headers indicate the acceptable media-types, encoding, languages and character sets on the client. -
From,Host,RefererandUser-Agenthave details about the client that initiated the request. -
Authorization: used by the client to provide credentials which can be further used by the server to authenticate the request. This is useful for accessing password-protected resources. -
If-prefixed headers are used to make a request conditional—the server returns the resource only if the condition matches. Otherwise, it returns a304 Not Modified. -
Referrer: contains either the partial or absolute address of the requesting page.
There are many other HTTP headers in use. Read more about headers if you want to understand some of the intricacies of the HTTP protocol.
HTTP Responses
The response is similar in structure a request message, except for the status line and headers.
- status line: includes a status code that indicates whether the request succeeded (status code 200) or why the request failed. It also includes the HTTP version and a very brief description of the status.
- headers: additional information about the response. For example the content type, or information about the server.
- body (optional): the content of the response. For example this might be the HTML content of a requested web page, or the binary data of an image.
A successful response from the server will have a status line similar to HTTP/1.1 200 OK.
Response Headers
Just like in a request, the response message can have a number of headers. Here are some commonly-used response headers:
-
Age: the time in seconds since the message was generated on the server. -
ETag: the MD5 hash of the entity and used to check for modifications. -
Location: used when sending a redirection and contains the new URL. -
Server: identifies the server generating the message.
The HTTP Response can also have a collection of entity headers. The role of the entity header is to offer meta-information about the message body. Here are some typical entity headers:
-
Allow: defines the set of methods a resource may support. If the resource is not supported, you will receive a status code405 Method Not Allowed. -
Content-prefixed headers indicate the response media-types, encoding, languages and character sets on the message payload. For instance,Content-Encodingis used to compress the transmitted data. -
Expires: indicates the date and time when the response will become invalid, so the resource should not be cached past that point. -
Last-Modified: carries details of when the server believes that the response resource was last modified.
Status Codes
With so many theoretical concepts, you might be feeling a bit drowsy. But please hold on. We are going to end our theories with the HTTP response status codes. Every response from the server will have a status code. The status code is important and tells the client how to interpret the server response
1xx: Informational Messages
This class of codes was introduced in HTTP/1.1 and is purely provisional. The server can send an Expect: 100-continue message, telling the client to continue sending the remainder of the request, or ignore if it has already sent it. HTTP/1.0 clients are supposed to ignore this header.
2xx: Successful
This tells the client that the request was successfully processed. The most common code is 200 OK. For a response to a GET request, the server sends the resource in the message body.
-
200 OK: the request was processed successful and the response body will contain any requested content. -
202 Accepted: the request was accepted but may not include the resource in the response. This is useful for async processing on the server side. The server may choose to send information for monitoring. -
204 No Content: there is no message body in the response. -
205 Reset Content: indicates to the client to reset its document view. -
206 Partial Content: indicates that the response only contains partial content. Additional headers indicate the exact range and content expiration information.
3xx: Redirection
This requires the client to take additional action. The most common use-case is to jump to a different URL in order to fetch the resource.
-
301 Moved Permanently: the resource is now located at a new URL. -
303 See Other: the resource is temporarily located at a new URL. TheLocationresponse header contains the temporary URL. -
304 Not Modified: the server has determined that the resource has not changed and the client should use its cached copy. This relies on the fact that the client is sendingETag(entity tag) information that is a hash of the content. The server compares this with its own computedETagto check for modifications.
4xx: Client Error
These codes are used when the server thinks that the client is at fault, either by requesting an invalid resource or making a bad request. The most common code in this class is 404 Not Found, which I think everyone recognizes.
-
400 Bad Request: the request was malformed. -
401 Unauthorized: request requires authentication. The client can repeat the request with theAuthorizationheader. If the client already included theAuthorizationheader, then the credentials were wrong. -
403 Forbidden: server has denied access to the resource. -
404 Not Found: indicates that the resource is invalid and does not exist on the server. The other codes in this class include: -
405 Method Not Allowed: invalid HTTP verb used in the request line, or the server does not support that verb. -
409 Conflict: the server could not complete the request because the client is trying to modify a resource that is newer than the client’s timestamp. Conflicts arise mostly for PUT requests during collaborative edits on a resource.
5xx: Server Error
This class of codes are used to indicate a server failure while processing the request. The most commonly used error code is.
-
500 Internal Server Error: the server had some sort of crash or internal error that stopped it from fulfilling the request. -
501 Not Implemented: the server does not yet support the requested functionality. -
503 Service Unavailable: this could happen if an internal system on the server has failed or the server is overloaded. Typically, the server won’t even respond and the request will timeout.
Tools to View HTTP Traffic
There are a number of tools available to monitor HTTP communication. Here, we list some of the more popular tools.
Undoubtedly, the Chrome or Webkit inspector is every web developers’ favourite. The Network tab, in the Chrome Developers Tools menu has become much more useful in recent years. A lot of information can be gathered from here about HTTP requests and responses.
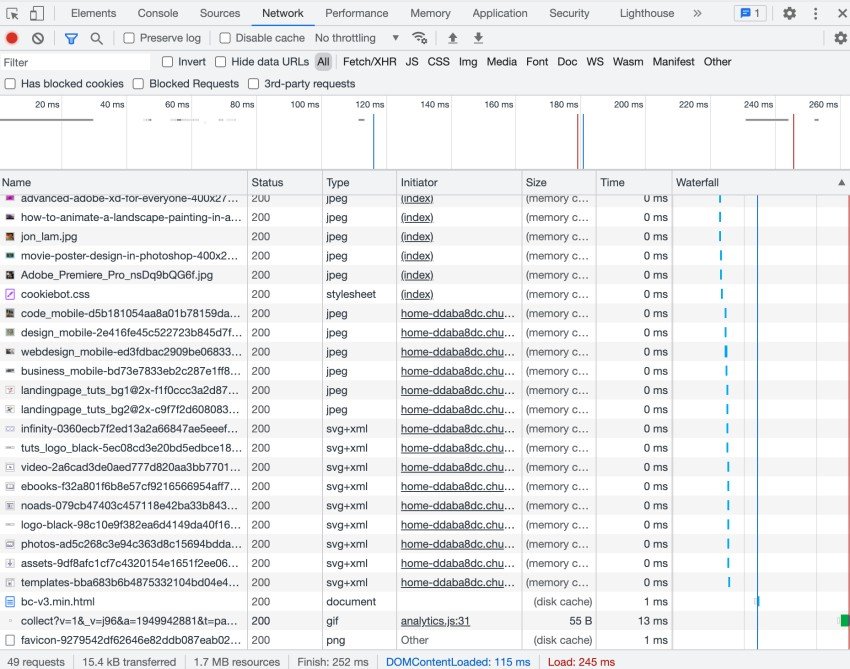
There are also web debugging proxies, like Fiddler and Charles Proxy or OSX.
Using HTTP in Web Frameworks and Libraries
Finally, let’s see how the request-response pair is used by frameworks. As an example, let’s begin with ExpressJS for NodeJS.
Receiving a HTTP Request With Express
If you are building web servers in NodeJS, chances are high that you’ve considered Express.
Express provides a simple API for writing web servers. I won’t cover the details of the API. Instead, I’ll show you a an example of how Express uses HTTP requests and responses.
Express Hello World
const app = express()
app.get('/', (req, res) => {
res.send('Hello World!')
})
app.get('*', (req, res) => {
res.sendStatus(401);
})
app.listen(3000, () => {
console.log(`Example app listening on port ${port}`)
})
In this example, we set up a handler for a GET request with the path /. When the server receives this request, it will respond with 200 OK and the message body will be Hello World. The server will listen on port 3000. For GET requests to any other path, the server will return a 401 Not Found error.
You can learn more about using Express in the official documentation or in our in-depth tutorial on creating a REST API.


Sending an HTTP Request With the Fetch API
Finally, let’s see how to make an HTTP request from the client side. This used to be done with jQuery, but modern browsers have the Fetch API built-in. And, the syntax does not get any simpler.
GET Requests With Fetch
To request data from the server, use fetch("https://example.com/something.html"). This returns a Promise, which you can await to get the response.
let response = await fetch('https://example.com/movies.json')
let data = await response.json();
console.log(data);
In the example above, we sent a GET request to https://example.com for the movies.json resource. We await the response, and then extract the response body as JSON.
POST Requests With Fetch
To post data to the server, with an optional payload, the client makes use of: fetch('https://example.com/profile', { method: 'POST'}). Again, this returns a Promise which you can await to get the results of the request.
let response = await fetch('https://example.com/profile', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
})
if (! response.ok) {
console.log(`POST failed with status ${response.status}`)
}
In this example, we’re submitting a post request to the profile endpoint of https://example.com.We want to send JSON data to the server, so we set the Content-Type header to application/json. Then we stringify our data to JSON and send it in the request body.
Conclusion
Congratulations, you have now mastered the basics of HTTP request and response! Now, you will be able to use the protocol in your application. Also, you should be able to choose the right HTTP verbs and headers for your use-case.
Divya Dev is a front-end developer more than a half a decade of experience. She is a grad and gold medalist from Anna University.
