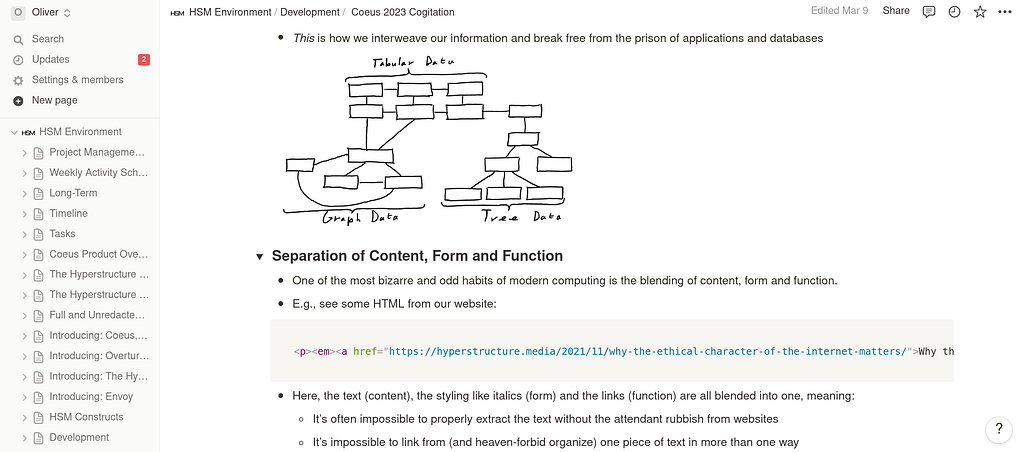
We are not masters of our information, but we can be if we build information systems shaped like human consciousness.
Why are our information systems places where ideas go to die? Why are they clogged with shallow, soulless filler? Why can so few of us, and fewer organizations, gain any level of mastery over our documents, ideas, and data?

I think that the reason is that our information management systems are neither powerful enough nor properly shaped like human consciousness. Essentially, I claim — drawing upon the field of cybernetics — that in order to manage and master today’s immense range and variety of information, we need immense variety within our information systems.
I am not claiming that these systems should be very complex — or even necessarily that complex at all — but rather that they should at least mirror the capabilities and range of human consciousness. Without tools like this, our information will swallow us up: perhaps you, dear reader, feel like it already has.
There is an alternative: to devise, build and use tools that have the nuance and humanity necessary to set down and manage our ideas. But, one might ask, what might these tools look like? How can we measure their humanity? I hope in this essay to:
- Narrowly define a word that I have used a great deal in various articles up to this point to refer to tools which are naturally suited to the expression human thought: “ideisomorphism”
- Explain in terms of cybernetics why our information systems need this quality in order to function properly
- Build a quantitative framework for measuring the extent to which tools are ideisomorphic
Preamble: cybernetics
I’d like to draw upon the field and terminology of cybernetics to help me. Cybernetics — much misunderstood because of the over-used “cyber-” prefix — is the study of regulating systems: machines, air traffic, companies, etc. It precedes and coexists with our thinking around modern computing: cybernetics does not necessarily require computers, but its ideas apply to computer systems and their operation, and computer systems are useful in cybernetic setups.
I refer you to two cybernetic concepts:
1. The good regulator
The concept of a “regulator” is fundamental to this field: this term describes a system designed to achieve a particular set of conditions within another system. For example, a thermostat is a regulator designed to maintain a temperature, such as in a house. A thermostat is a very simple regulator; more complex regulators include air traffic control organizations, highway management systems with variable speed limits, enterprise resource management systems, etc.
The theorem of the “good regulator” by Roger C. Conant and W. Ross Ashby posits that “Any regulator that is maximally both successful and simple must be isomorphic with the system being regulated. [emphasis mine]” In common English: a regulator that can actually regulate the desired system and that is not overly complicated should contain a structure that is the same as the structure of system that it regulates.
I think that our information systems have the role of the regulator in our global corpus of literature and, more broadly, information: the nexus of written material, information, databases, that we need to parse, create, edit, re-use and organize is the system and our information tools are the regulators.
I think that today there are few information systems that are good regulators in this respect: they lack what I call “ideisomorphism.” This is the quality of systems that are naturally suited to the expression human thought, or, in more cybernetic terms, it is when the regulator contains a model of human thinking.
A good regulator must be isomorphic with the system it regulates — information systems must therefore be isomorphic with human consciousness (ideisomorphic).
2. The purpose of a system is what it does (POSIWID)
This heuristic, derived by famous cyberneticist Stafford Beer, reminds us that we have choice over the systems that we create and, therefore, when we build systems that do not achieve the desired outcome we are effectively choosing the actual outcome they engender, regardless of their stated goals.

{kind=link}
I say, therefore, that the deranging information environment of today is a choice, and urge humanity to choose differently.
Our tools, thus unable to control the information they generate, leave the corpus to grow into bizarre and inhuman configurations: rigid hierarchical and table structures that crush the life out of human thinking; endless, unattributed copy-pasted popcorn-content and screenshotted memes; corporate and government databases with incorrect data or that force you to fill in data they already have; personal and company file systems where information rots, forgotten.
Having talked about ideisomorphism for some years now, I will in this essay attempt to give it a mathematical definition and provide a means of quantifying it.
My claim is that — while human consciousness is fundamentally and importantly non-quantifiable — the aspects of our mental faculties concerned with conveying information can be quantified in a mathematical and logical way, which we can use as a means of scoring the suitability of given software tools according to the extent to which they are capable of expressing our ideas.
This, I hope, we can use as an index (of many) against which to judge our machines.
What is isomorphism?
Before we can discuss ideisomorphism, we will need to introduce isomorphism. Isomorphism is a mathematical concept, describing a relationship between two systems whose structures are the same. Specifically, two systems are isomorphic if you can map each element of one system onto one element in the other system, and transform back and forth without losing information.
A parallelogram and a square are isomorphic: you can map each of the four sides of the parallelogram to the sides of a square, and its four corners to the corners of the square. However, a triangle and a square are not isomorphic, because the square’s extra side and corner mean that a one-to-one mapping is not possible.
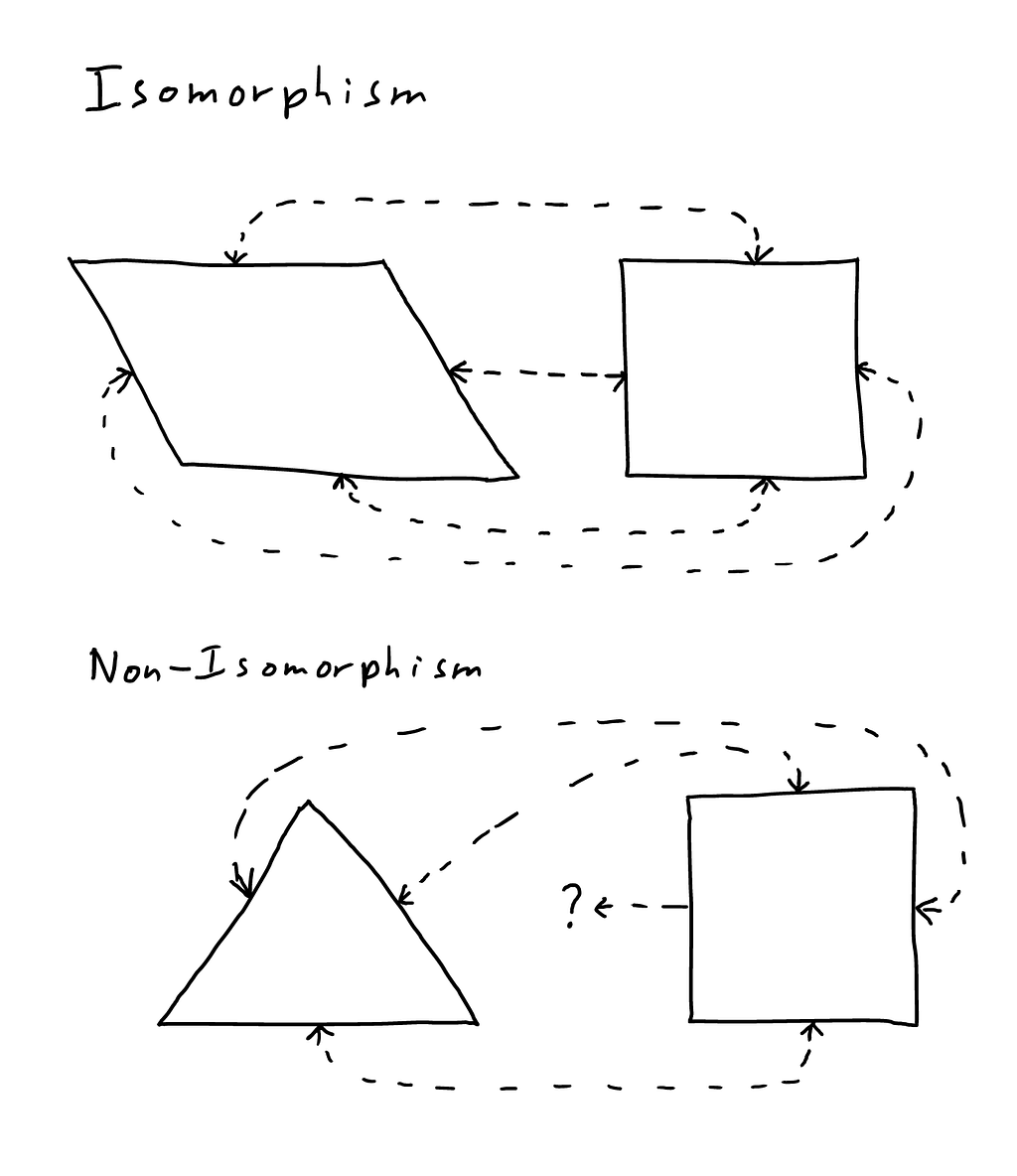
A parallelogram and a square are of course different in other respects, such as their angles, with mathematicians describing such as a relationship as “up to isomorphism” — a square and a parallelogram are isomorphic up to their angles.
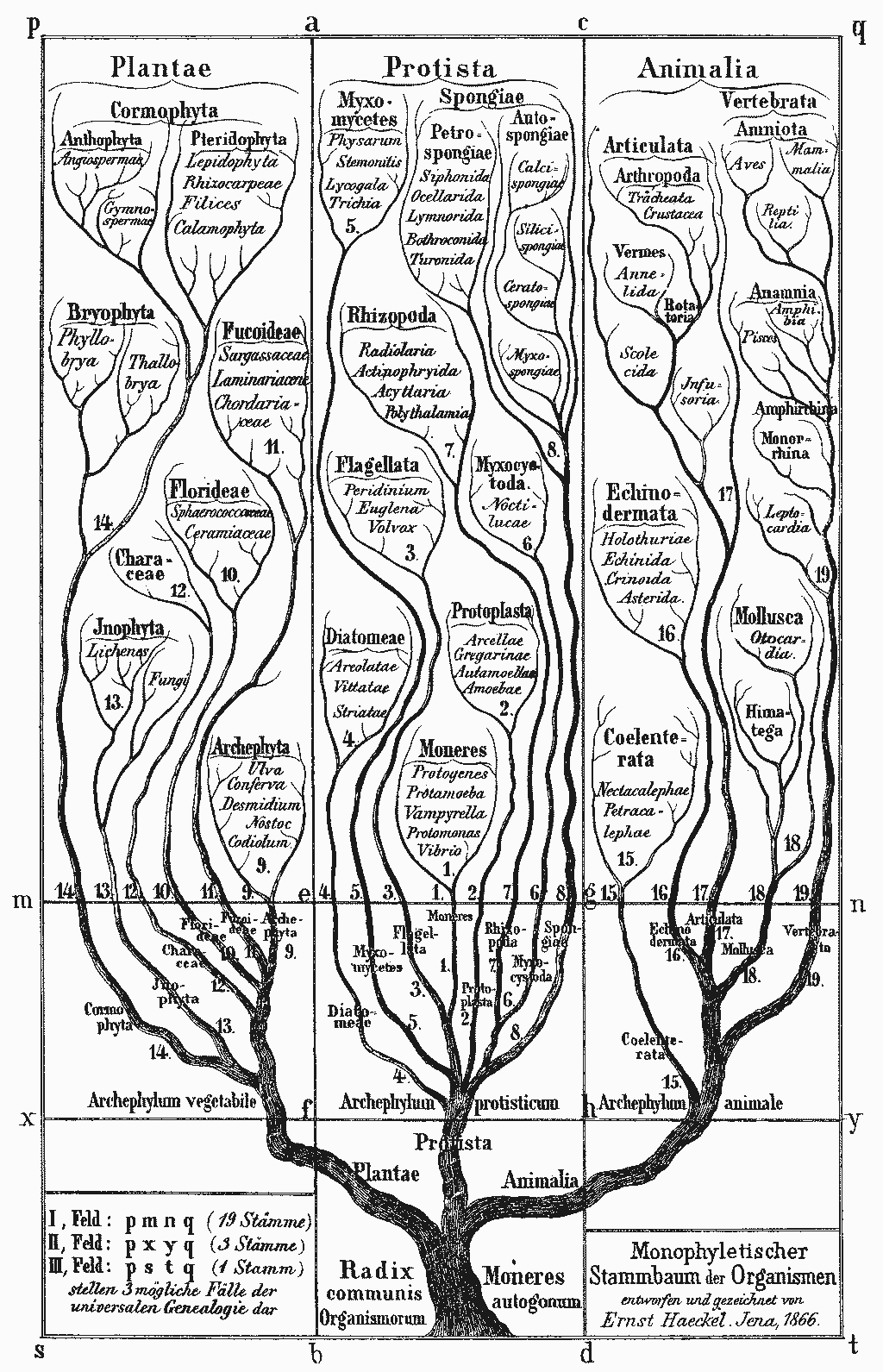
The structure of multicellular life-forms is described as “the tree of life” because it resembles the structure of a tree (branches, splitting off into innumerable smaller branches, with each branch coming from one “mother” branch only). The tree of life and an actual tree are isomorphic up to the living details of an actual tree: the bark, cells, leaves, etc.

{kind=link}
#/media/File:Haeckel_arbol_bn.png){kind=link}
The concept of isomorphism is useful not least because it allows us to establish a comparison between things with respect to structure and put to one side things that are contingent. When we uncover an isomorphism, we are uncovering similarities between different things, which therefore can indicate that their causal structure may be similar or the same.
This yields a captivating field of possible analogies between mathematical, philosophical, natural, economic, etc. systems. For example, Benoir Mandelbrot in his book, The Misbehavior of Markets, discusses the isomorphism between the changing prices in the stock market and his fractals. Discovering this similarity led Mandelbrot to predict that modern explanations of markets — which assume prices follow a purely random pattern are dangerously wrong — with serious consequences for how we ought to manage our money.
What is ideisomorphism?
Ideisomorphism is the property of systems that:
- Have the necessary fidelity to represent human thinking
- Make it natural to do so
Mathematically, an ideisomorphic system must have an interface with a one-to-one correspondence to each of the important elements of the area of human thinking that it is attempting to model. We should be able to flip back and forth from the real human system to the computer system without losing information.
We can therefore derive three levels of ideisomorphism:
- Particular ideisomorphism: an arrangement of information in a computer that has a one-to-one correspondence of its parts to the particular system that it is modeling, e.g. a spreadsheet program storing a school register.
- Class ideisomorphism: a computer program that has a one-to-one correspondence between its parts and the human system that it is modeling, such as a word processor that has a user interface element for each aspect of writing. Note that the goal here is not to model a particular item (such as the register referenced above) but to model the class of thing, thus a program with such a model can represent all things within that class.
- General ideisomorphism: a platform/substrate on which computer programs are built that is subtle enough to achieve a one-to-one correspondence to the fabric of human thinking.
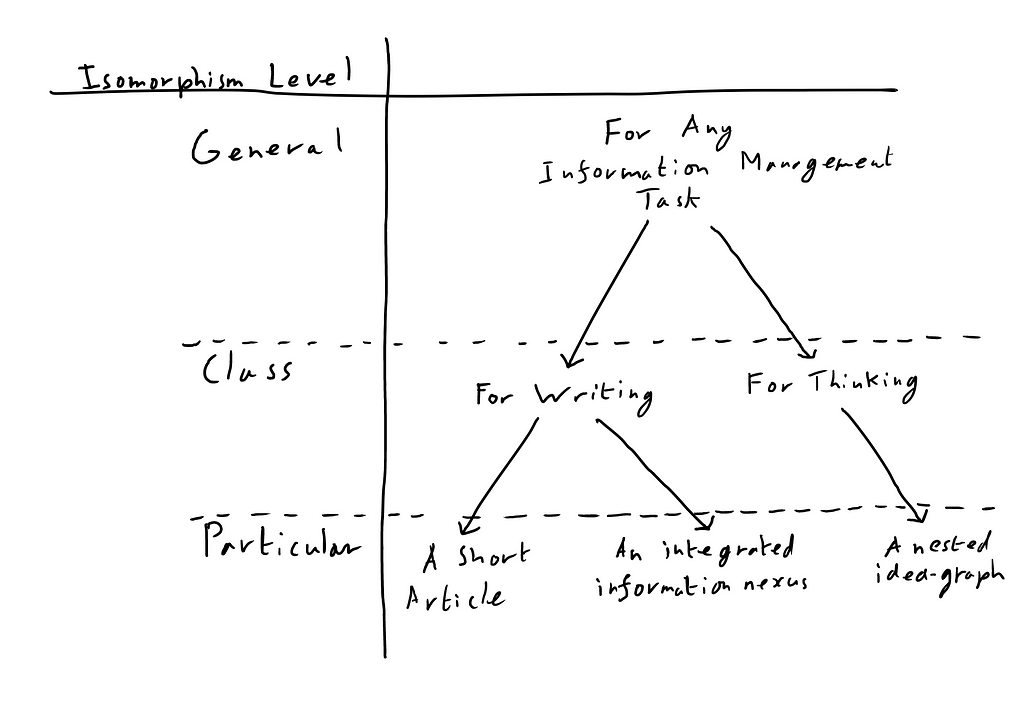
Any generally ideisomorphic system can contain and generate any class isomorphic system, and any class isomorphic system can contain any particular ideisomorphic arrangement within its class.
A particular ideisomorphism can be defined, therefore, as a particular set of objects and the relationships between them.
A class ideisomorphism is defined as the set of permitted object types and relationship types between them: for basic writing, for example, the objects would be characters, words, sentences, etc. and would include some facility for building an overall linear relationship that can be read from beginning to end.
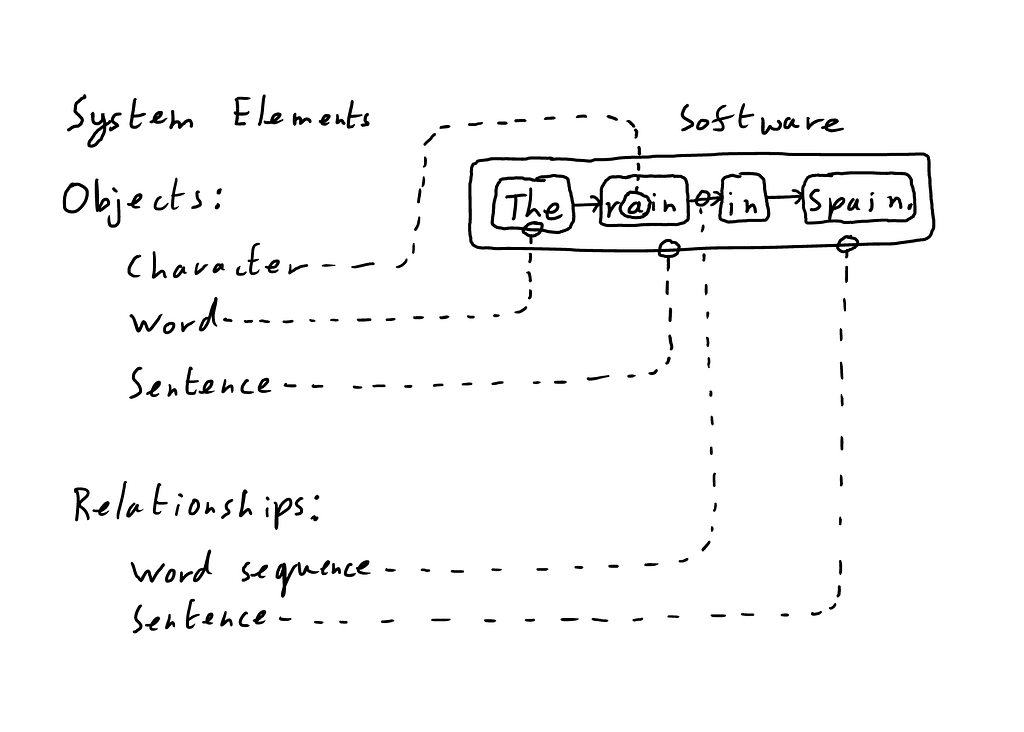
A generally ideisomorphic system is, surprisingly, the most simple: all that is required is the concept of the thing and the relationship. A thing, which we at my company HSM call a “node,” is something that has either no structure (e.g. a single character) or strictly linear structure (e.g. a simple word).
The relationship is the unit of structure, collecting any number of nodes and other relationships, without restriction: a relationship might contain two nodes to link them together, or might contain a set of sets to form a file system, etc.*1
With these entities plus the principle that everything should be uniquely identified and addressable, one can build a system of arbitrary nuance and therefore truly general ideisomorphism.

The main objective of my company, HSM, is to build ideisomorphic computer systems: to the extent that humanity’s information systems lack this quality, our ideas must be distorted, even destroyed, to fit within computers; and the more ideisomorphic we make our computers, the more natural it will be to work with them.*2
When ideisomorphic systems finally gain mass adoption, I expect people to experience something like William Blake described in The Marriage of Heaven and Hell:
If the doors of perception were cleansed every thing would appear to man as it is, Infinite. For man has closed himself up, till he sees all things thro’ narrow chinks of his cavern.
Quantifying ideisomorphism
Going back to our original discussion of isomorphism, recall that systems are isomorphic when there is a one-to-one mapping between each element in one system and each element in another. Note that the goal here is to quantify structure and the processing of structure: formatting is therefore considered contingent for our purposes (though still important). Therefore, I’d like to quantify ideisomorphism by asking the following questions about the relationship between a system of human thinking and a given piece of software:*3
- Of the operative objects in your system, how many are available in the software?
- Of the operative relationships in your system, how many are available in the software?
- Of the total number of operative actions in your system that correspond to consistent (and therefore possible) software actions, how many are available in the software?*4
For clarity, what does it mean for an object, feature or action to be available in software?
I say that objects and relationships should be:
- Uniquely identified and referenceable
- Visible (not necessarily all the time)
- Selectable and movable (ideally with a manageable number of clicks)
Actions should be maximally singular, i.e. if the user must labor over a (possibly repetitive) string of tasks to do one coherent thing, the action is not properly available within the software.
One expresses the ideisomorphism score as the number of things you can do out of the total number of things we should be able to do (e.g. 1 out of 3 or 33%). To get the total score we simply sum up the total of both counts, giving us the potential and actual performance for the software.*5
Separating the noun-oriented questions (regarding what objects and relationships are available) from the action-oriented questions, we can also derive a two-part rating that gives us a feel for the expressive and the instrumental capabilities of the software. We can even graph this:
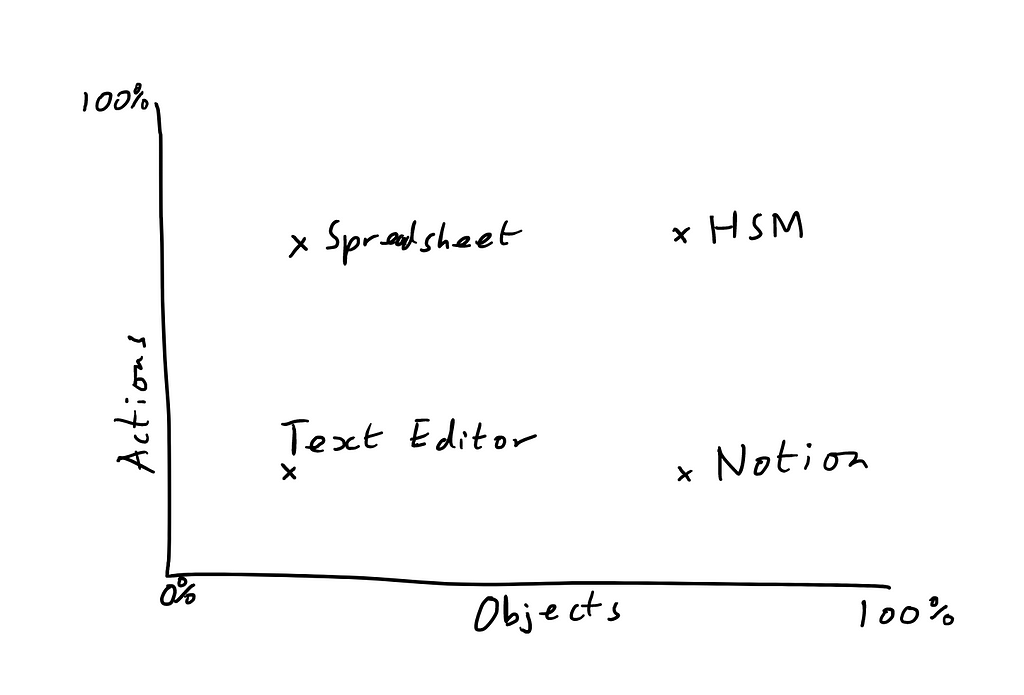
The graph above is a crude expression of the relative ideisomorphism of different systems:
- Simple text editors don’t allow you to do that much or create many different things (this is often just fine given what you actually need to do with a text editor);
- Spreadsheets allow you to do lots of stuff (formulas, sorting, etc.) but don’t have much diversity among the things you can create
- Notion allows you more freedom for how you create and structure things, but without all the capabilities of a spreadsheet
- HSM will give both: immense fidelity of objects, relationships and actions
While the ideisomorphism score is an attempt at quantifying a relationship, it is of course quite open to opinion: indeed, the whole computer world is build on people’s opinions on how things should be — some people dress their opinions up as technological truth.
I don’t deny that anyone can claim any number of bogus operative objects/relationships/actions that they say they need in order to create absurd scores. There are two responses to this: one is to explain in detail why we need what I say we do and build it to show you; another is to defer to fairly consistent and useful fields of study, such as grammar, where there are well-evidenced and argued operative elements like words, clauses, sentences, etc. that may or may not appear in our software.
To demonstrate my proposed score, I will assess a human system and the attendant software: writing and word processing.
Writing versus word processing
For the human art of writing we have software tools called word processors: the defining modern example of this tool is Microsoft Word, with Google Docs, Libre Office and others providing alternatives.
1. Of the operative objects in your system, how many are available in the software?
Limiting ourselves to the absolute fundamentals of English (I advocate for the equivalent level of depth for all languages, but can speak only English well enough to advocate for it) the objects of our language are:
- Characters
- Morphological sub-word parts like roots and suffixes
- Words
- Grammatical sub-sentence constructs like phrases and clauses
- Sentences
- Paragraphs
- Nested higher organizational groupings, like subheadings, headings, chapters, etc.
A word processor can create characters, but no word processor that I have heard of can uniquely identify parts, words, sub-sentence units, sentences, paragraphs, sections or chapters. Now, most word processors have the ability to create a heading, but this is a half-measure: it is merely a specially formatted piece of text (that can sometimes be linked); there is no construct that actually contains the entire section in and of itself.
Notion, an excellent hypertext program, offers something of an intermediate structure called a “block”. A new block is created every time the user hits enter, so they can be single words, sentences, paragraphs, etc. and the user can drag them around. This is helpful but a half-measure: if the sentence is a block then the individual words, phrases and clauses comprising it cannot be blocks, and whatever is a block must be separated by a carriage return, precluding a world of structure.
Score: 1/7
2. Of the operative relationships in your system, how many are available in the software?
Linear relationships: In word processors, the structure is always linear: one character leads to the next. The word processor genre therefore gets one point for satisfying this single aspect of written structure.
Grammar and morphology: However, there is a world of structure missing within the sentence and the word. For example, the sentence “John hit the ball.” can be broken into a noun (John) and a verb phrase (hit the ball), which can be further broken into a verb (hit) and a noun phrase (the ball) which can be further broken into the definite article (the) and a noun (ball).
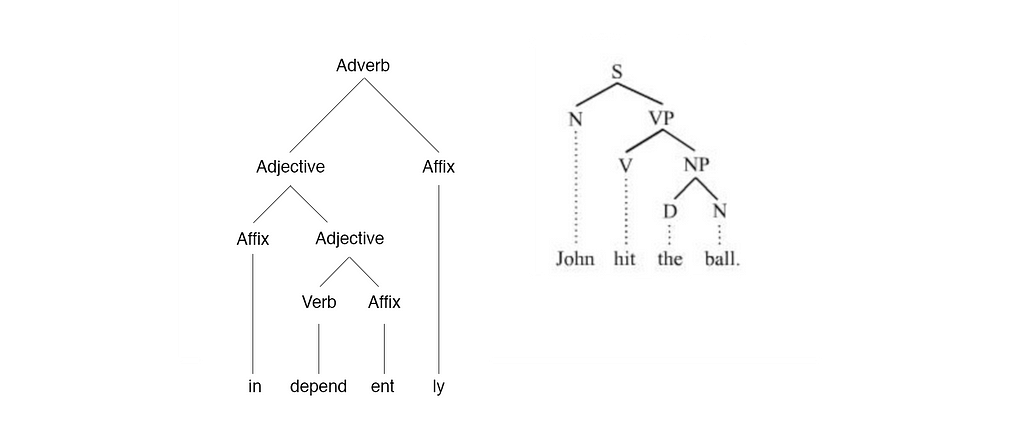
This more natural and descriptive way of structuring writing is completely absent from our software, despite its immense promise as a tool for writing, editing and teaching.*6
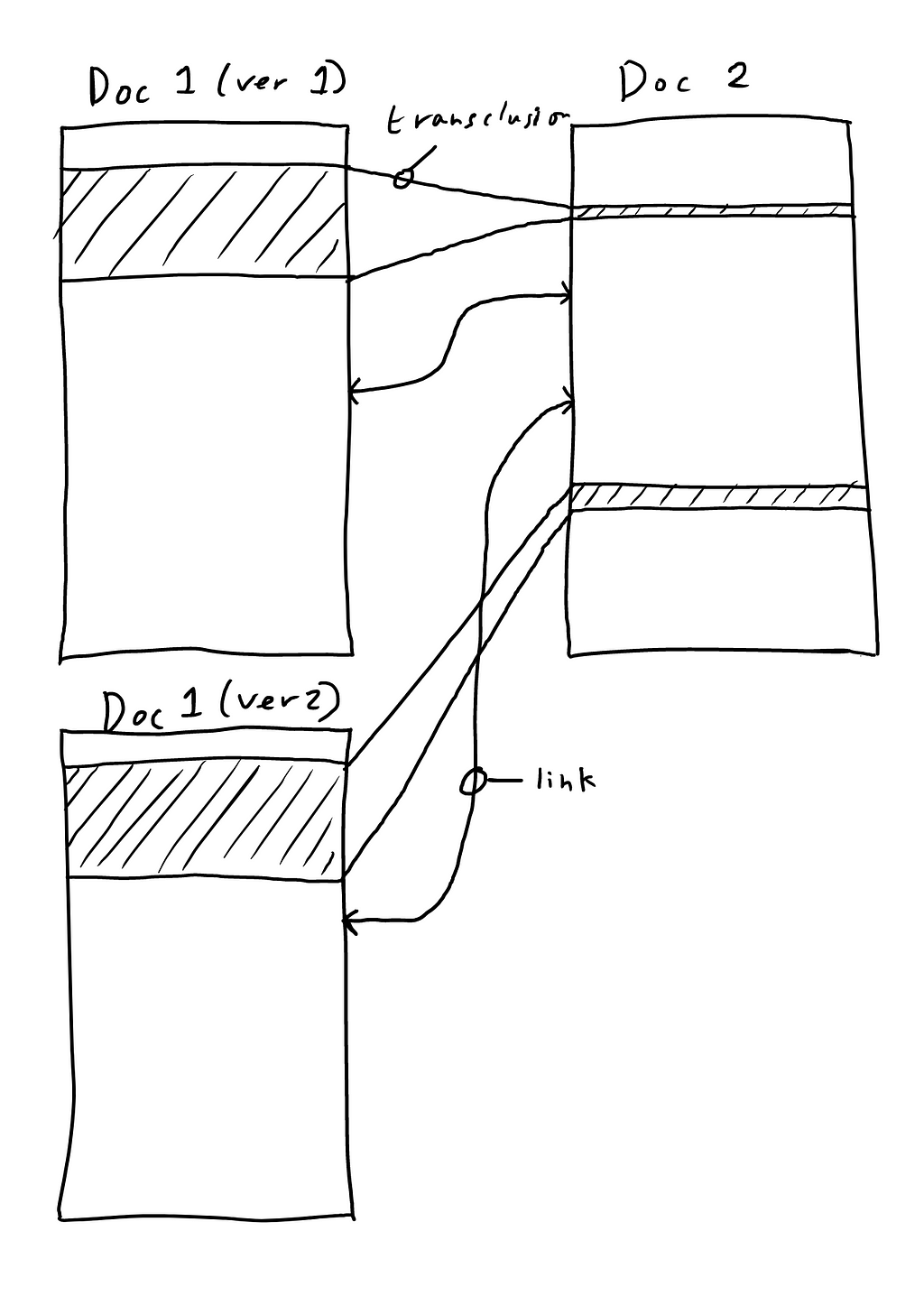
Re-use: The ability to arbitrarily re-use and organize pre-existing material is quite absent also. By this I mean not copy-pasting, but referencing prior material to show it additional times without copying and to build structure, i.e. “this idea belongs in both these headings”.
Because modern word processors are strictly linear, hierarchical and build razor-wire fences around individual documents, they preclude a given sentence being in more than one place although this is perfectly logically coherent and possible on our computers. Ted Nelson defined this concept in the 60s and called it “transclusion”.
Links: Then, finally (for now), we have links. Nelson (again) explained decades ago that writing should be visibly connected to the material it cites, connected via links that are visible from all endpoints. Rather, today’s links are one-way: Shakespeare can reference the King James Bible and link back, but when you look at the Bible there’s no evidence of that connection. Real links are, decades after Nelson originally described them, still totally absent from our word processors.
Score: 1/4
3. Of the total number of operative actions in your system that correspond to consistent (and therefore possible) software actions, how many are available in the software?
Obviously word processors can do a lot of what’s needed for a system for writing:
- Creating original material (typing characters into a document)
- Editing material: Delete, copy/paste, find/replace
- Undo/redo, track changes
For what they can’t do, I’ll limit myself to just two items here, for brevity:
Cut and paste (not to be confused with the modern construct of adding a single piece of content to memory to be output elsewhere): As Ted Nelson put it, “Writing is about re-writing, and re-writing is about re-arranging.” Nelson identified how all modern writing tools lack the paper technique known as cut and paste: the art of cutting a piece of writing into pieces, and freely moving them around into a new structure.
This is possible today only in a plodding, one-thing-at-a-time manner: imagine being able to hit a button and explode your article into individual paragraphs/sentences, then drag and drop these into a new arrangement. This is more than possible, but is denied us.
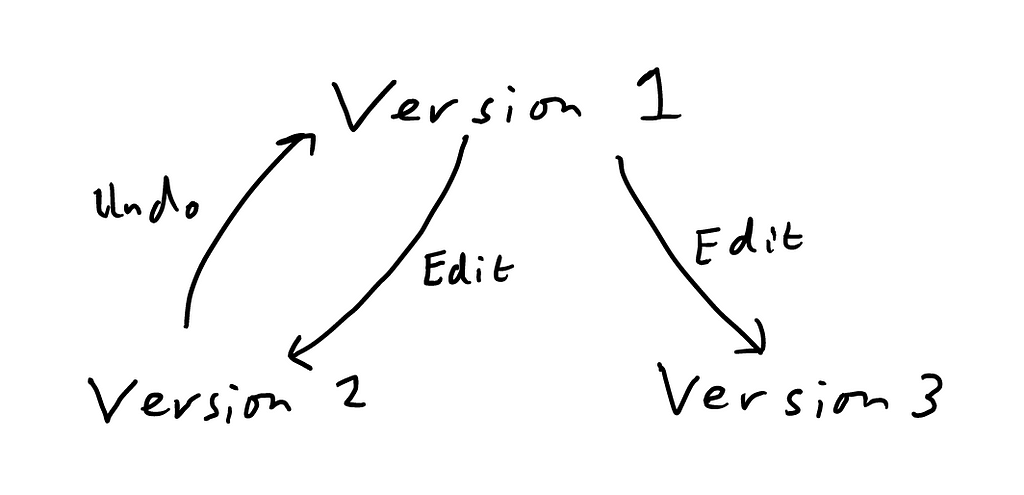
Version history tree: Then there’s another Nelson concept: the version history tree (I thought I had invented this myself, then found that Nelson references his in Computer Lib). You may, dear reader, have made some progress with a document (call it version 2), then hit undo a significant number of times to return to a previous state (version 1), then edited the document again.
This action (editing a document after hitting undo) destroys the previous latest version (2). If you decide that 2 was in fact the best version, you are usually done for. This arrangement is totally unacceptable — who on Earth thought that our version 2 wasn’t worth preserving, especially given that one can destroy it by typing a single character accidentally.
The solution to this is simple: every time you hit undo the word processor should create a new branch of the version history tree and preserve that progress. It will be there waiting for you if you want it again.
Score: 3/5
Totals:
- Objects: 1/7
- Relationships: 1/4
- Actions: 3/5
Aggregated total: 5/16 or a 31%
Composite total: 18%:60%
There you have it: as a genre, by my estimation, word processors are less than 50% capable of modelling human thinking (being quite charitable). In composite, while they have more than 50% of a crude model of possible actions available, are extremely poor when it comes to the objects and relationships one can create.
I won’t hide the fact that this scoring system is redolent with its status as a first attempt, but I hope that it is something that people can use in good faith to benchmark the humanity of our software.*7
Synthesis
Returning to “the purpose of a system is what it does”, I ask the question: What do our purported information systems actually do?
Well, they have been known to manage information, but I and everyone to whom I’ve spoken regarding corporate documentation systems agree that these constructs (documents, filesystems, etc.) are in fact where information goes to die. There is no coherent way to govern and find the information, so it is endlessly lost, reinvented, and rots.
More broadly, the Web, whose stated intention is to manage the world’s knowledge, in fact optimizes for the overproduction of shallow, soulless material (or, at its most malign, clickbait).
So what is wrong with our system? I say, quite simply, that our information systems are not good regulators: they are brutally simplistic and do not contain an isomorphism of the domain that they purport to control. It is no surprise, therefore, that we humans have no control over the information nexus that we claim to create.
Essentially, we are trying to create literature, and are handed a system for handling streams of characters.
I think that the main argument against the approach that I’m recommending — that is, expanding the breadth of structure and action that is available to the user, particularly to match the structure of human consciousness — is that it will increase complexity.
I don’t think that this is the actual reason why things are the way they are today. Rather, in the early days of computing we built things in ways that are basic and natural to computers, i.e. based on hierarchies, tables and strings of text, and these things stuck.
That said, reducing complexity is a relevant goal in some circumstances. Indeed, R. Bush and D. Meyer state in RFC 3439 that “complexity in networking systems is the primary mechanism that impedes efficient scaling.” Meanwhile, visibly complex user interfaces can be overwhelming for new users.
But I think that the admonition of all complexity in all scenarios is just as dangerous. Indeed, if you wish to do complex things, the complexity has to go somewhere: Bush and Meyer note that “the complexity of the Internet belongs at the edges, and the IP layer of the Internet should remain as simple as possible.” — this is to say that the thing that interconnects networks should be simple, and that the computers and applications they run should accept the necessary complexity.

The corollary of this in user interface is that stupidly simple software offloads the complexity either to the user — who is stuck shunting text, copy-pasting, or who simply fails to express their ideas — or to other applications (such as Google, whose job is to index content that should already be indexed), which ends up giving us more complexity, incompatibility and distortions, and on the part of the user: misery.
Milton Glaser put it excellently:
Being a child of modernism I have heard this mantra all my life. Less is more. […] But it simply does not obtain when you think about the visual of the history of the world. If you look at a Persian rug, you cannot say that less is more because you realize that every part of that rug, every change of colour, every shift in form is absolutely essential for its aesthetic success. You cannot prove to me that a solid blue rug is in any way superior.



.jpg){kind=link}
{kind=link}
{kind=link}
There are some scenarios that demand complexity, and without the requisite complexity — or in cybernetic terms “variety” — it will crop up somewhere else and will usually. When it does crop up it will probably be in the wrong place, as you didn’t decide to put it there.
I think, therefore, that before we ask, “How do we reduce complexity?” we should ask, “What does this system need to do, and how do we present the necessary complexity/variety to users in a way that is natural, consistent and proportional?”
The trade-off in our software is rarely actually between simplicity and complexity, but between ugly complexity and graceful complexity. Graceful complexity is, I think, our main hope for not being washed away by the modern deluge of information and for using technology for its proper purpose: increasing the scope and leverage of human ideas and action.
My company, HSM, is working on something better. If you would like to be part of this, please reach out here.
*1 It’s important to note that most things that are properly sets of relationships, but are given to us by software as nodes. e.g. Documents are really nested sets of interlinked and nested words, sentences, paragraphs, but are stored by software as blocks of characters. This is a problem also for navigating a file system: few file systems can really show you inside the file without actually opening it with the attendant program (e.g. Microsoft Word): What’s inside? Who knows!
*2 It’s important to emphasize that the goal here is not to create an exact copy or even to model all aspects of human thinking or anything for that matter. This is obviously impossible and the attempts are not particularly desirable: as I mentioned in my previous essay, I’m interested in technology that increases the scope and leverage of human action (of which the pivot is structure); superficially more “real” constructs—like “metaverse” constructs like virtual bank offices and skeuomorphic interfaces — are an awkward waste of time.
Rather, the goal here is to build systems that are isomorphic to human thinking up to that which is contingent.
*3 It’s important to note that under the heading “detail” I include both information storage and user interface. Any given element should appear both as an accessible function in the user interface and should be addressable in the backend data.
For example, in the powerful diagramming tool Miro, one can create shapes and connect them together with arrows to build mind maps, but there is no way for the user to export the arrows in a coherent way that would allow them to be imported into another tool or Miro environment.
One mustn’t forget, also, that all the tools of description and comparison that I use are themselves subject to the same criticism: concepts like that of a sentence, clause, word etc. are part of an artificial system we created to describe our language. Artificial systems (both conceptual like our ideas of language and physical like computers) cannot describe nature completely, and there is indeed something impossible to pin down about human nature, life, communication, etc. that probably will never be described in a consistent, logical sense — and this is quite fine.
Rather, when I talk about ideisomorphism and point to places where it is missing, I am pointing to areas of consistent behavior, thinking and systems that could be described by computers but aren’t, and not to the ineffable aspects of humanity (that arguably make us most interesting).
*4 This is obviously a tough one to define, so it requires a good deal of grace. By “consistent” I mean an operation that can be defined by a rule or set of rules and that doesn’t require the computer to break the rules or access information not available to it: select all words beginning with “s” is consistent, select all words that I’m thinking of is not consistent.
*5 There are of course other important considerations that relate to the quality of our experiences with software, notably the extent to which it is humane, speed (which is important to give interfaces a feeling of immediacy), reliability, etc.
*6 You should (and may already) be aware that the relevance of tree-like structures like this for grammar is controversial: there are other approaches, and the user should be able to take their pick and opt out completely, if they wish.
*7 No software is perfect, not least because potential features are unlimited but time is limited. Please do not, dear reader, interpret the above as an unfair indictment of software developers who are unable to make software that is perfect for me at the expense of all other concerns; rather it is an indictment of a software industry that is stuck in a narrow conception of information systems, at the expense of undeniably human concepts like grammar and structure.
Meanwhile, I’m calling not just for more features but for a simple and generalizable substrate from which users can create their own features, obviating the need for developers to throw finite resources at infinite problems.
Indeed, before Notion (to my knowledge) there was no concept of a uniquely-identified, movable “block” — people didn’t fail to build them before because they ran out of time, they didn’t set out to build them at all. Notion, having built them, is loved by millions.
![]()
The purpose of a system is how we shape it was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.