
Data ethics principles and processes are useful, but they are often of limited use when it comes to addressing the social and environmental harms of the data economy. This post is about using creative R&D to build data technologies that embed a different set of values from the ground up, balancing exploratory with experimental approaches to prove what works.

There’s a reason that data trusts are named one of the 10 breakthrough technologies of 2021 — they are a way of challenging the status quo. Governments and companies have mishandled data time and again. GDPR and other data protection regimes have technically given power back to the people, but in practice, individuals can’t be expected to take responsibility for evaluating abstract and unknown risks every time we want to look something up online. All too often, clunky data consent boxes invite us to click ‘yes’ and hope for the best. These data protection regimes also commonly miss the fact that data about you is also data about others. Anouk Ruhaak points out that just as your genetic data can reveal information about your family, what you share on social media can affect your friend’s insurance premiums.
More than ever before there is a growing public awareness that the way we choose to collect, share and use data is important. On one hand, the COVID-19 pandemic has demonstrated how public health data can be used to hold governments to account for their policy decisions. The incredible achievements of the scientific community have also shown the scale of potential innovation that can be enabled by increased data sharing.
On the other hand, documentaries such as The Social Dilemma and high profile data scandals have made the potential harms of data mainstream news. The Cambridge Analytica and Facebook scandal revealed the extent of commercial data profiling and the risks to democratic processes when combined with adtech. The UK’s algorithmic A-level grading fiasco which gave students from state schools lower grades is just one of countless examples of how social inequalities are amplified through data.
Currently, the dominant set of values embedded in the data economy are closed, extractivist, monopolistic, and often driven primarily by capital gain. Whilst data ethics principles and procedures are valuable for embedding critical consideration into data practice, those using them to minimise harms are usually limited by the fact they are locked in a system that does not favour the little guy.
A data trust is an independent entity that stands up for our data rights in a particular setting, just like a trade union stands up for our labour rights. Models of ‘data stewardship’ such as data trusts show the potential for doing data differently- challenging the established ideas of who gets to say what data is collected and how it is used. Exploring data models that rethink binaries and hierarchies, consider context, and make labor visible offer an opportunity to embed alternative values into technology and it’s inevitable impact on the world.
But data trusts are just one part of this picture- models like data cooperatives and data unions tackle similar problems in different ways. And there are other simple mechanisms that can be used to change things up such as embedding community panels in engineering cycles to inform key decisions. Whilst this is a relatively new field, organisations like the Open Data Institute, Ada Lovelance Institute and The GovLab have been doing brilliant work framing it. There are also many examples where these models are already in use- ODI has published 6 case studies showing different models operating in different contexts. These include UK Biobank which has been running for 15 years to support biomedical research in the UK, and HiLo a maritime safety startup that has reduced lifeboat accidents by 72%, engine room fires by 65% and bunker spills by 25% through data sharing.
Jared Keller’s great work on the Data Access Map demonstrates the breadth of different approaches, and how in practice they often act as an assemblage of different ideas, technologies and governance structures. The right model for any particular purpose is often very dependent on context- the varying goals, industries, type of data being shared, and many other factors have a huge influence on what is the most effective model.
But whilst acknowledging there are loads of options is exciting, how do you figure out where to start and what to try? Over the last few years, I’ve worked with the Open Data Institute and Wellcome Trust on a range of research projects looking at new ways of collecting and sharing data (including the first pilots of data trusts). What I have learned is that to find the right model for your context, it’s useful to take an R&D approach.
The two phases I describe below have been inspired by Meg Doerr’s description of how Sage Bionetworks use the applied ELSI research framework for biomedical research. By framing them in an R&D context, I hope to show how that type of approach is relevant beyond an open science context.
R&D for data
Research & development is one of those terms that is used in lots of different ways but generally, it describes ways of making a new or better thing as opposed to new knowledge (hence the development bit). Most people associated the term R&D with industrial product development, but it’s also used in creative settings. The difference between these two forms of R&D is that one tends to be more experimental- answering a specific question or goal by generating empirical evidence, and the other is more exploratory, often looking to answer more abstract questions or goals where you’re making sense of something that not well defined in a more holistic way.
It is of course very reductive to suggest that experiments are for scientists and exploration for creatives. Science doesn’t function without creative thinking and creative practice is often a process of extensive experimental rigour. However, you can align the experimental vs exploratory forms of R&D with the ideas of design thinking vs art thinking. Design thinking is a method for shaping a product or service, it’s a single direction. In contrast, Ars Electronica describes art thinking as “detecting social and technological trends that are not yet given a name, and giving a form to communicate those micro-trends tangibly.” It’s a broader process that can encompass all the possible directions of travel.
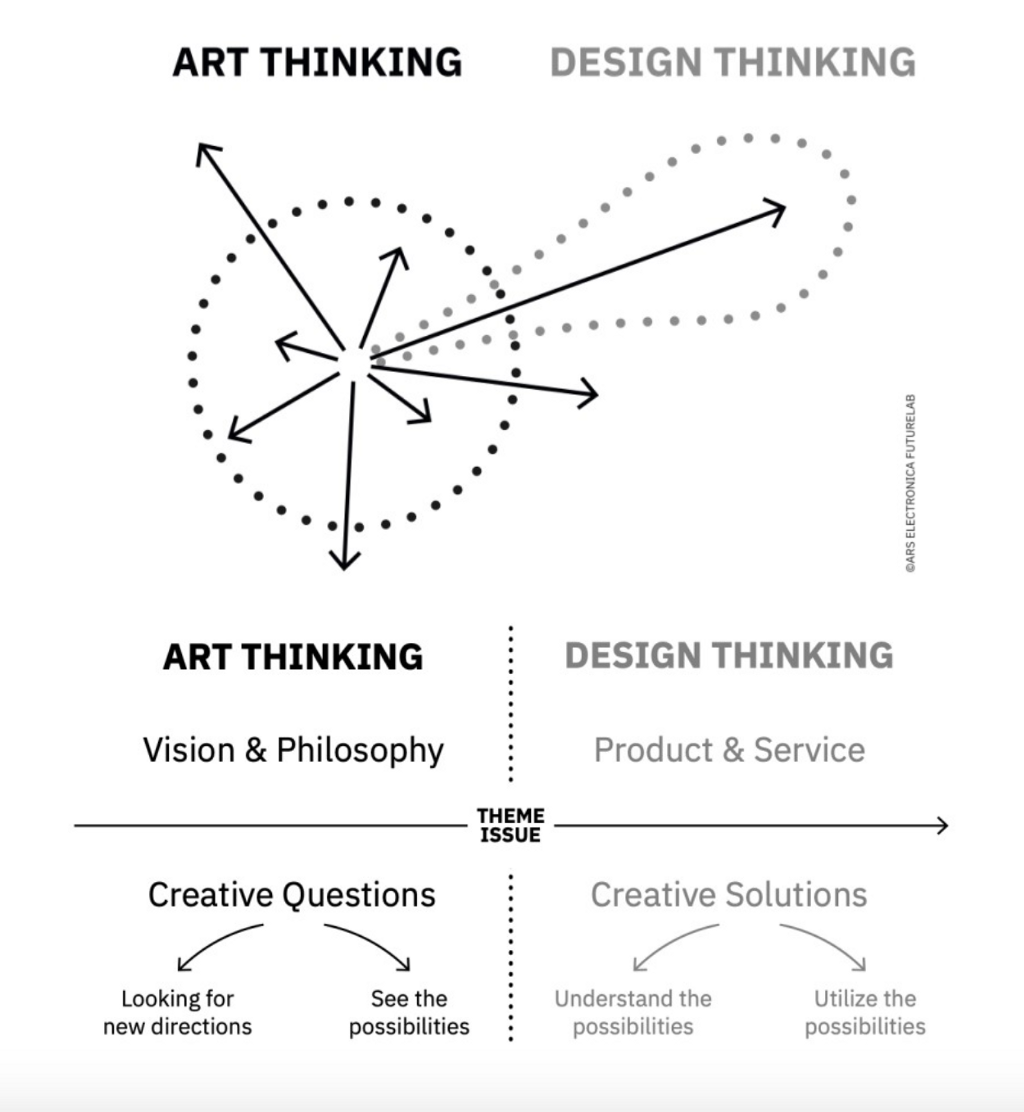
Because the field of data stewardship is still developing and there are so many potential options, to find the right model for your purpose you need a combination of both the empirical and the non-empirical- the design thinking and the art thinking- but not at the same time. First, you need to use the broad, exploratory approach to develop an understanding of what you could do, and then you can use the design thinking, experimental approach to test your ideas and gather evidence of what works and why.
1) The art thinking/ exploratory/ non-empirical bit
This is the bit where you consider all the different things you might want to achieve, and figure out all the questions you need to answer in order to achieve it. I have found it useful to use speculative design methods and futuring along with developing logic models or a theory of change. This thinking can then be used to design the applied, experimental phase- figuring out what you’re going to build, who you’re going to test it with, and what it’s going to evidence.
It’s important to think about both the practical considerations and the values you want to prioritise. Considering both of these factors will help narrow down the list of potential data models you might want to test.
The practical stuff could include the outcomes you want to enable with data you are collecting or using (eg: new forms of research, better products and services etc…). The values side of things is where you think through how you might challenge the status quo and do things differently. Some questions that can be useful to ask are:
- Who gets to have a say in how data gets collected, shared and used? What groups who are impacted by the data use don’t have a say?
- Who gets access to the data and who doesn’t?
- Are there ways for other people or communities to get involved or challenge decisions and what would happen if there were?
Some data stewardship models are not technically or practically feasible right now, but that doesn't mean it’s not important to consider all options. The empirical phase can be used to start gathering evidence to inform what those speculative models might look like, even if they can’t be built and tested yet.
One of the tricky but really important aspects of doing R&D for data is that you’re collecting data about data, so it’s really important to ensure that your testing phase is open and participatory. Finding ways of giving groups who aren’t usually included in tech engineering equal authority in decision-making is critical. These groups can help you work out which models to test, why and how. If they aren’t ‘experts’ in the subject it’s your responsibility to equip them with the knowledge they need to make their own independent but informed decisions.
2) The design thinking/ experimental/ empirical bit
This is where you build prototypes and use them to gather evidence to inform the questions you have identified in the first phase. If resources allow, it’s useful to consider using three following methods in some combination:
- Applied — Building prototypes and pilots help develop practical insights into technical requirements and regulatory requirements
- Quantitative — Using the prototypes to test multiple hypotheses with recruited participants in doing to generate quant evidence of what variables are most effective.
- Qualitative — Using participatory approaches like deliberative democracy exercises help you to understand nuance and context
Using the evidence you gather you can make a call on the best model and approach for your data.
For Example…
The graphic below describes the project I am working on with Wellcome’s Mental Health team at the moment- the Global Mental Health Databank Feasibility Study. The points at the top show the thinking that happening in the non-empirical/ art thinking phase:
- The practical aim is that Wellcome is looking to enable new forms of research into interventions for depression and anxiety in young people by collecting longitudinal data about their lives.
- The value part is that they’re looking to do so in a way that gives equal power to the young people contributing their data and the researchers who might access it. They also want to enable research beyond WEIRD (Western, Educated, Industrialized, Rich, and Democratic) countries because people in other areas are often left out and mental health research is highly context-specific.
For the second phase, Wellcome have commissioned Sage Bionetworks working with a consortium of mental health researchers and groups of young people with lived experience of anxiety and depression across India, UK and South Africa. They are collaboratively designing and delivering a testing phase that gathers rich evidence to indicate whether it is feasible to achieve the practical aims, with the values expressed. If it is not, they will not proceed.
The lower sections of the graphic describe how they’re doing that using applied, quant, and qual methods. We’re posting updates and learnings for the GMH Databank project regularly on the Wellcome Digital blog.


![]()
How to build tech that does things differently was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.