Co-authored with Josh Lovejoy

What’s in a voice? What is it about the way someone speaks that makes them memorable? Why do subtle imperfections in speech — like the thoughtful pauses and false starts when thinking on one’s feet — help us perceive a person as sincere or trustworthy? And conversely, why is it that when someone sounds overly polished and prepared, it subtracts from their humanity?
In the field of text-to-speech (TTS), exploring questions like these in a quest to replicate the human voice has felt like the stuff of speculative fiction until very recently. We’ve now reached a tipping point where neural networks have enabled the generation of synthetic media that is nearly indecipherable from human speech. But what’s especially distinctive about this new era of TTS is the speed and ease with which we can create a convincingly human-sounding voice.
With standard or “traditional” TTS, building a synthetic voice that doesn’t sound too robotic takes at least 10,000 recorded sentences from a single speaker. In contrast, neural TTS requires as few as 500 utterances to successfully capture a person’s unique vocal characteristics. The resulting synthetic voice is fully dynamic in tone, affectation, and vocal nuances. Even the breaths and common “ums” inherent to physical speech are present, as though produced in unison with a brain, lungs, and vocal cords. This newly created voice can express and emote in ways that are very different from the original recordings. It can even speak in a different language.
The opportunity for creating delightful experiences with synthetic voice is immense. Neural TTS can be used for creative expression and offer life-changing assistance. Virtual agents based on fictional personas, entertainment venues like video games and audio books, educational applications like interactive lessons or guided museum tours, assistive technology, and real-time translation are but a few of the intended and appropriate possibilities.
But the technology can also be weaponized to harm individuals and society. It has the potential to defame character, erode trust in public institutions, undermine authentic journalism, and jeopardize national security. Demonstrations of AI-generated deepfakes have depicted heads of state speaking words they did not utter, in languages they do not speak. Synthetic voice has the potential to deceive a public that is unequipped to recognize or question whether an artifact is legitimate. And with each passing day, it’s getting easier to manipulate digital media online. This advancement reveals an urgent need for us to wrestle with its implications for personal identity and social fabric.
We rose to the occasion by diving deeply with Microsoft Research security specialists, signal processing experts, and AI researchers, gathering their perspectives on watermarking capabilities, detection of synthetic content, and adversarial malware and detection models. These conversations focused on multiple forms of synthetic media, but with audio as the central element. The upshot: The state of the art is such that we’re no longer able to fully determine whether voice media is real nor can we assert its provenance. And there aren’t legal frameworks in place yet for addressing the technology’s proper use. What we need to do is envision a more intentional and accountable future. That vision can guide responsible development, advocating for human rights and the well-being of at-risk communities.
This raises a spectrum of ethical considerations for us as user researchers and designers. We’re being called on to develop a new muscle in our practice, one that demands strength in areas that reach far beyond designing solely for consumer experience. We need to be thinking broadly about the personal and societal impact of our platforms. Our job is to design in a way that influences policy and keeps human concerns at the center of technology.
Mapping the ecosystem and bringing diverse perspectives
We have been grappling with designing effective guardrails for the responsible deployment of Microsoft’s Custom Neural Voice, a neural TTS service that enables our customers to create branded voices with dynamic speech. As we shaped this platform, we realized it was essential for our customers to not only to tap into the benefits of the technology but also to design against its pitfalls.
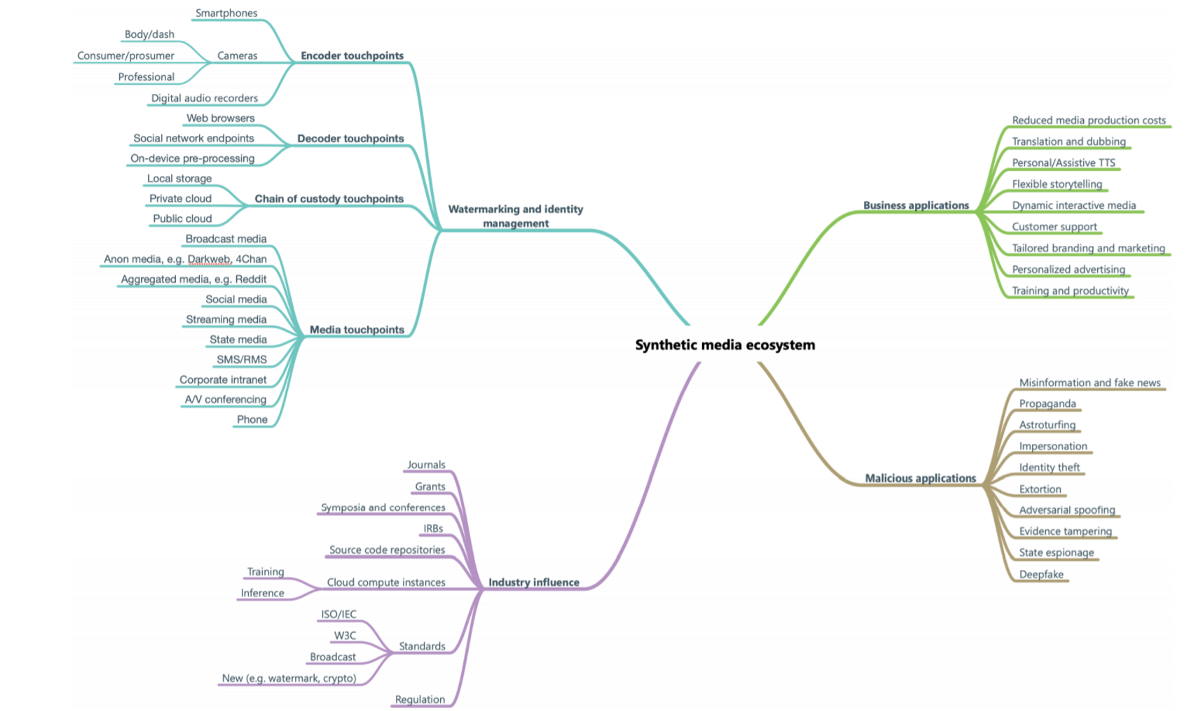
We started our process by mapping out the synthetic voice ecosystem. This helped us visualize not only the technical considerations of the platform but also its broad range of human touchpoints and applications.
With the landscape laid out, we could identify a broad range of stakeholders impacted by neural TTS, not just consumers. We conducted surveys and interviews for a harms and benefits analysis across diverse groups, from people with speech and language impairments to voice actors, those whose lives and livelihoods can be deeply affected by synthetic voice. Considering the technology’s potential impact, it’s not surprising we heard people express anticipation that ranged from eagerness to dread. A parent of an autistic child told us, “The quicker they can get to this technology the better … the sooner I can provide my child with technology to express his feelings the better.” Others were wary: “Someone could use it [synthetic neural voice] for a wrong reason … It could become an evil thing.”
Concerns like these propelled us to create guidelines that help our customers responsibly deploy Custom Neural Voice and review harm mitigation strategies with human-rights experts and. These include sets of disclosure design guidelines for synthetic voice interactions with consumers, as well as guidelines for explicit consent from voice actors who make recordings for voice fonts — the text-to-speech computer models that mimic their voice. We share our research-informed guidance here as groundwork that may help others with the ethical deployment of synthetic voice.
Design ethics tenets
Because there is no perfect way to prevent media from being modified or to unequivocally prove where it came from, we’ve focused on gating our Custom Neural Voice service to evaluate for its appropriate deployment. This vetting process results in an approximate 70 percent rejection rate, when applicants are unable to establish that their implementation will fit within the service’s human-centered guidelines.
We developed four design ethics tenets while actively seeking out feedback from our customers, including the BBC, Swisscomm, and Disney. When designing voice experiences, we collectively agree to:
- Protect owners of voices from misuse or identity theft.
- Prevent the proliferation of fake and misleading content.
- Encourage use in scenarios where consumers expect to be interacting with synthetic content.
- Encourage use in scenarios where consumers observe the generation of the synthetic content (for example, real-time translation).
Transparency and appropriate context are underpinnings throughout these tenets.
Considerations for voice talent
With respect to protecting voice owners, it’s important to acknowledge the voice-acting industry is directly impacted by neural synthetic speech. As one of our study participants told us, “Wow. I’m out of a job. If you can take a short amount of a voice actor’s voice, you can turn it into anything you want. … It is kind of scary.” At the same time, voice talent identified potential benefit from neural TTS capabilities, such as saving studio time and adding capacity to complete more voice acting assignments. Overall, they expressed a desire for transparency and clarity about:
- Limits on what their voice likeness could and could not be used to express.
- The duration of allowable use of their voice likeness.
- Potential impact on future recording opportunities.
- The persona that would be associated with their voice likeness.
To that end, our Custom Neural Voice customers must obtain consent from any voice talent they hire. This includes getting explicit written permission to use a person’s voice for a voice font and providing a disclosure for voice talent. This is a note that helps people understand the capabilities of the TTS technology their voices help to create. it lets them know what to expect when recording (e.g., number of lines required to produce a voice font) and gives them insight to the intended beneficial uses of the technology as well as examples of its appropriate and inappropriate use. Acquiring consent includes making voice talent aware of the intended contexts for the custom voice they are creating and discussing whether there’s anything they’d be uncomfortable with their voice font saying.
Design goals for synthetic voice
When businesses use synthetic voice in their applications, it’s critical to respect and maintain consumer trust. Our guidelines for responsible deployment of synthetic voice technology help maximize transparency. Letting people know when a voice is synthetic reinforces trust. Emphasizing the fundamentals of transparency and appropriate context, we identified four key goals for the designer:
- Reinforce trust: Design to fail the Turing Test without degrading the voice experience. Let users in on the fact that they’re interacting with a synthetic voice while at the same time enabling them to engage seamlessly with the experience.
- Adapt to context of use: Understand when, where, and how your users will interact with the synthetic voice so you can choose the right type and timing of disclosure.
- Set clear expectations: Allow users to easily discover and understand the capabilities of the agent. Offer opportunities to learn more about synthetic voice technology upon request.
- Embrace failure: Use moments of failure to reinforce the agent’s capabilities.
Disclosure
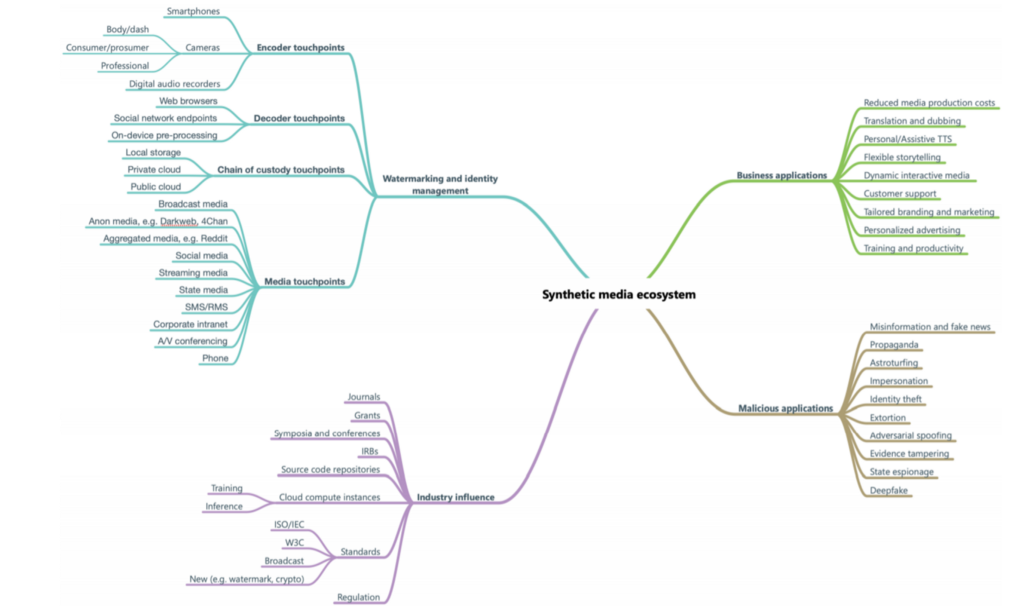
Context is everything. Fully understanding the voice persona and its intended use scenario determines the degree and timing of disclosure. The more human-like the persona is, the more people expect it to behave like a human. In some cases, a realistic synthetic voice may not be appropriate in sensitive scenarios where people expect empathy, such as when providing health assistance or obtaining personal information from a user. Being transparent with users to reinforce trust takes on even greater significance for long-term interactions, like when assisting people with disabilities.
There are times, like when playing a video game, people want to be absorbed in a convincing experience. They deliberately participate for the heightened entertainment value. But one thing our research taught us is that in consumer scenarios a delightful experience can be undermined if users do not discover until after the fact that a voice was synthetic. As one participant told us, “I wouldn’t like to talk to what I believe to be human only to find out it was a robot. It almost feels like a lie and it would make me mistrust the brand a little.” To help designers develop a sense of how to properly assess context and decide the right level and method of disclosure, we’ve developed a set of disclosure guidelines. These enable our customers to focus on specific steps for how and when to disclose the use of synthetic voice.
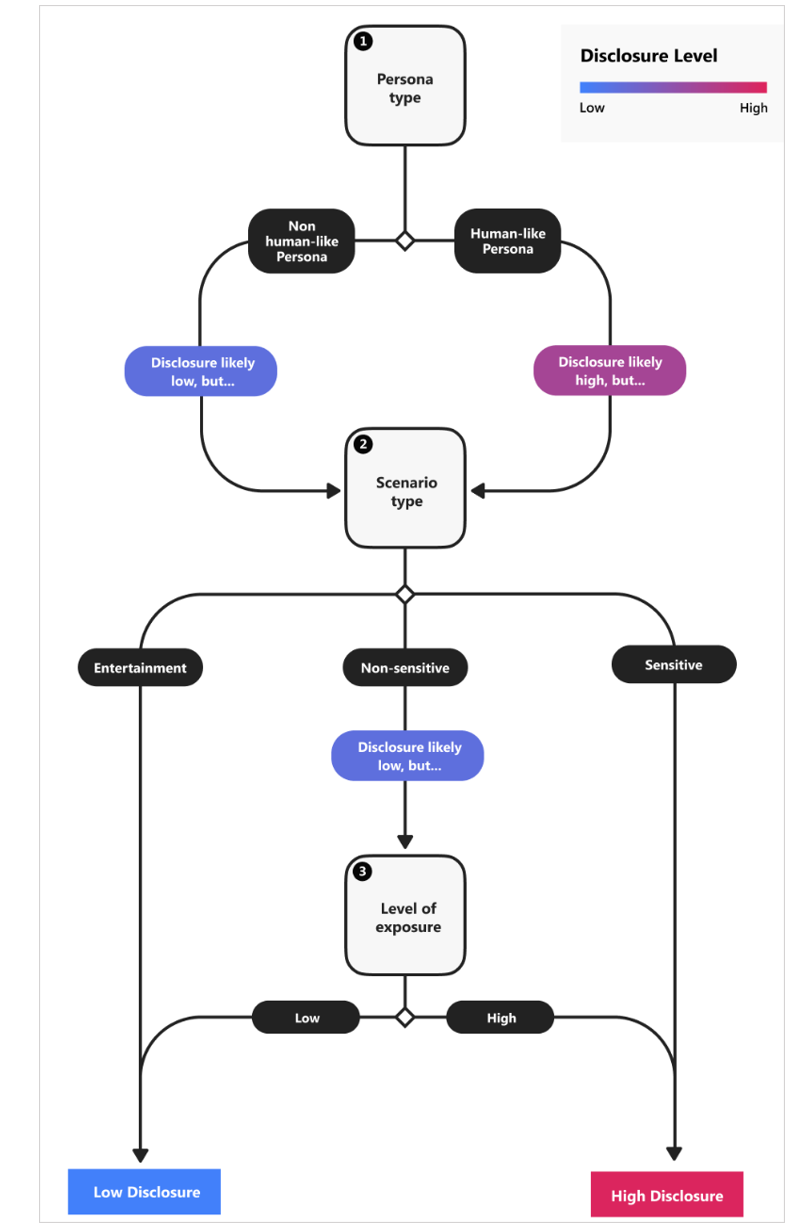
To further reinforce trust, we recommend user-testing for selecting scenario-appropriate voice types, as well as providing optional human support in ambiguous or transactional customer-service scenarios. As people in our study commented about the use of the synthetic voice as a travel agent, “Even if the computer voice speaking to you sounds human, it still doesn’t make me think that they can assist me in something as complex as finding the right travel plan .”
Design patterns
After deciding the proper disclosure level, designers can explore the array of disclosure design patterns that we’ve developed for explicit and implicit disclosure. The patterns start with an emphasis on transparent introductions that are communicated through multimedia. Patterns also cover the user’s first-time and returning experience, ways to give users control over customization and calibration of digital assistants, and provides opportunities to learn more about how the voice was made.
These patterns illustrate examples of ways of reinforcing transparency and offering users control and customization in various scenarios:

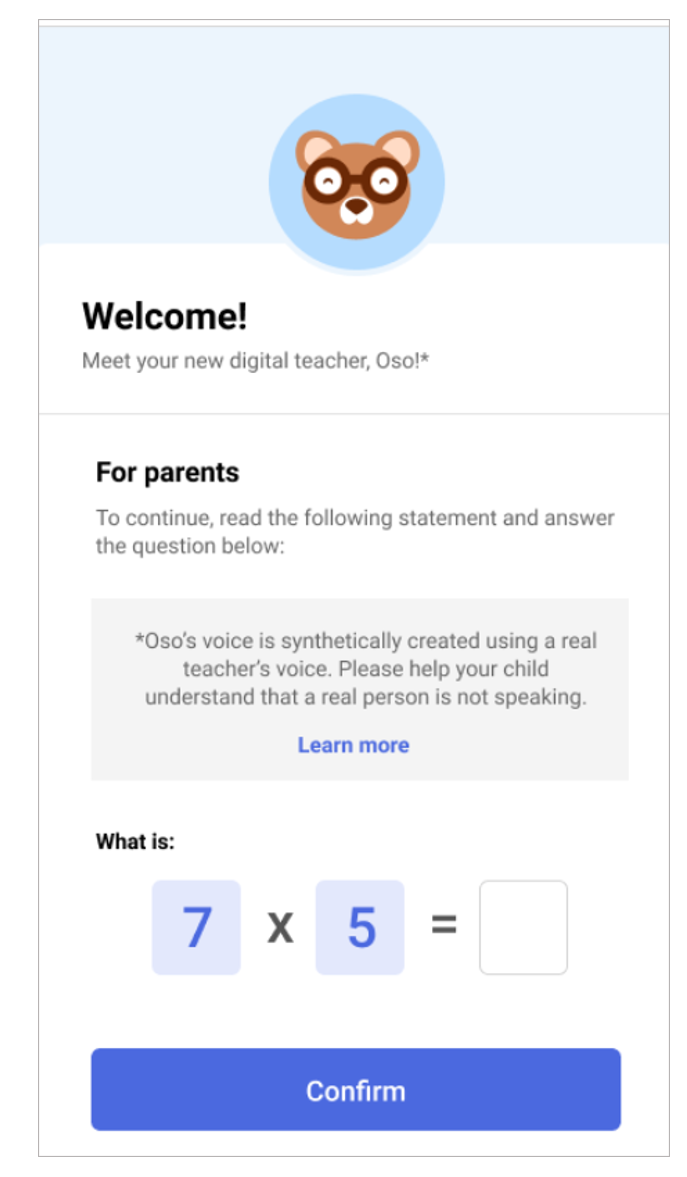
Accountability as our compass
Given neural TTS’s uncharted terrain, we rely on accountability as our compass, as we design in alignment with Microsoft’s principles for responsible AI. Disclosure and explicit consent are pivotal components of Microsoft’s Custom Neural Voice service. While we can’t promise perfect safeguards with this innovation, we can make sure the world knows where we stand and why. And we can help our customers do the same.
The authors would like to thank Angela Song, Ben Noah, Edward Un, Mira Lane, Sharon Lo, and Neeta Saran for their expertise and time on the project.

![]()
Custom neural voice: designing for human-centered policy was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.