Summary:
Different enterprise roles need different types of explanations for AI outputs.
Enterprise AI is a hot topic, but many organizations still struggle to achieve meaningful employee adoption and usage. This article focuses on what it takes to develop and deploy AI solutions that both organizations and employees can trust. In particular, it examines how AI explainability helps the people building enterprise AI (developers, system administrators, and domain experts) understand AI-system behavior, build trust in it, and support AI adoption. Because these technical roles bring different goals, expertise, and contexts, explainability cannot be one-size-fits-all.
AI Explainability in the Enterprise
Helping users understand how AI systems work is a core best practice for building trustworthy tools and products. Common approaches include creating traceability, source attribution, and explanations of reasoning and steps.
AI explainability is the degree to which an AI system’s decisions are understandable to humans. It helps users see how and why an outcome was reached.
AI explainability matters for anyone using or implementing AI, and the UX community has studied it extensively (see also IBM’s taxonomy of AI explanations in the sidebar to this article).
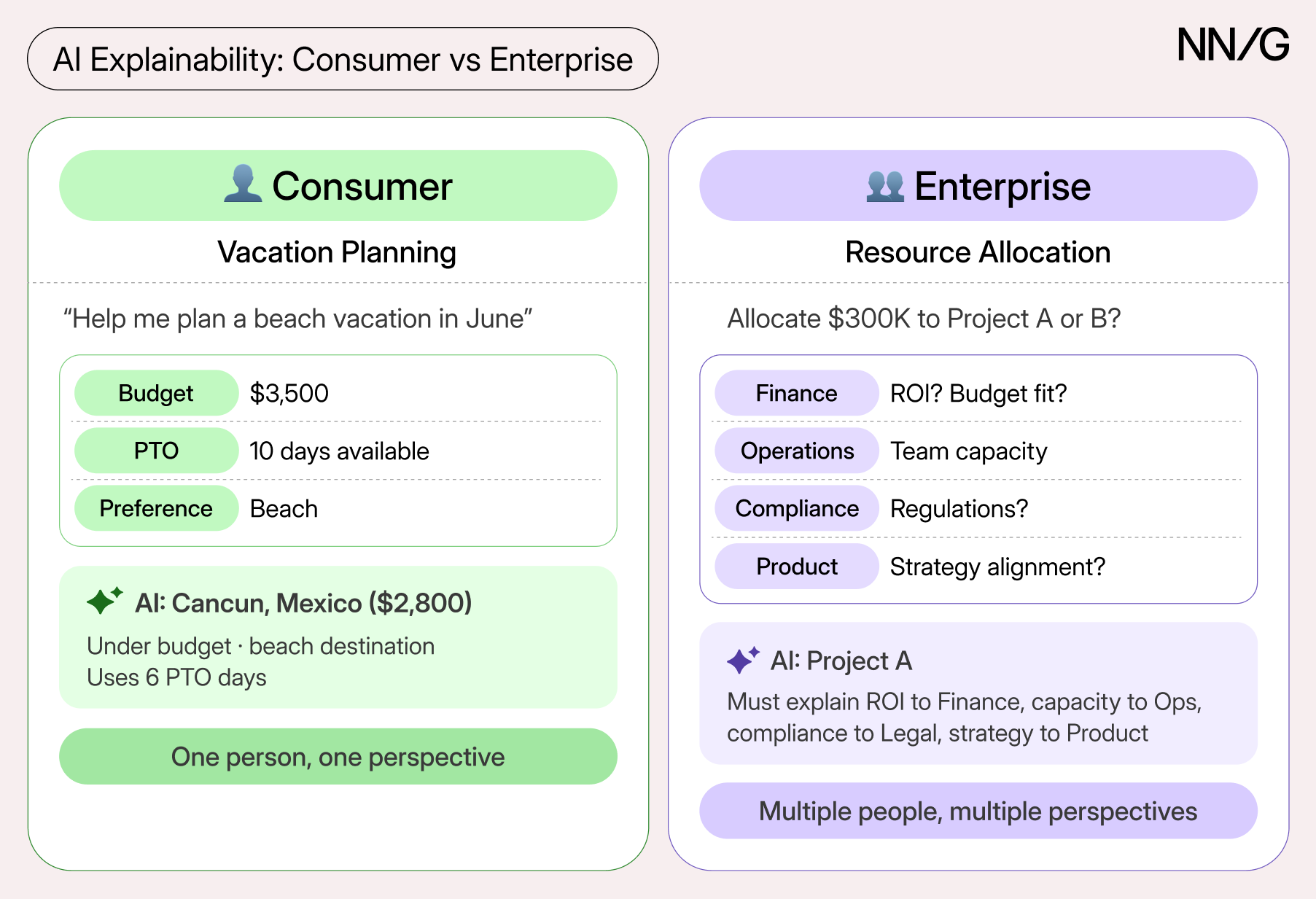
But most explainability guidance centers on consumer use cases (e.g., helping someone understand why Spotify recommended a song or how a chatbot arrived at a travel itinerary). Enterprise AI carries different stakes.
When organizations build or deploy AI tools and AI products for employees, the people architecting those systems affect livelihoods, data, and organizational risk. They must address governance, security, liability, and compliance before a single end user ever sees the interface. They sit in a unique position between the provider of a technology (e.g., a vendor) and the end user of it (the employee). Unlike booking a vacation, a misconfigured AI agent or an opaque model decision can have cascading consequences across the enterprise, ultimately impacting end users, trust, and organizational liability.
These stakes land differently by the role that interacts with the AI tool, product, or system. The person configuring the system, the security stakeholder approving deployment, and the subject-matter expert (SME) reviewing outputs all work with the same AI solution but need different kinds of understanding.
This is where jobs-to-be-done (JTBD) framework helps. The configurator validating an AI agent, the security stakeholder approving deployment, and the SME reviewing AI-assisted outputs each have different goals and therefore need different explanations.
In enterprise settings, explainability is how trust is built with the people responsible for approving, designing, deploying, and maintaining AI solutions.
Three Categories of Enterprise AI Users
In enterprise environments, AI systems are architected and configured by people with different goals, responsibilities, and levels of technical comfort. The AI explanations required by these people need to be built into the AI platform or administrative tooling by the vendors of these systems.
While there’s no perfect explainability taxonomy of enterprise-architect roles, it’s useful to define three categories, each mapped to a distinct job to be done.
|
Role |
Who they are |
Job to be done |
|
AI consultants & governance leads |
AI experts, centers of excellence (CoEs), governance leads, solution architects |
Define best practices, evaluate AI against security and governance standards, and advise on responsible deployment across the organization |
|
Builders |
Platform admins, developers, configurers, operation managers |
Translate business needs into working AI solutions through hands-on configuration, development, and maintenance |
|
Domain experts |
Process owners, business managers, service-desk leads, analysts, and others who understand the workflow context that AI needs to fit into |
Identify AI opportunities and improve AI outputs by contributing their specialized domain knowledge over time |
(One role that is absent from this taxonomy is the enterprise-system end user. That’s not because the end users don’t need AI explainability; rather, it’s that their explainability needs deserve separate, dedicated attention that is outside the scope of this article. Instead, this article focuses on the roles involved before the system reaches end users and on the level of explainability these roles need to build confidence in the AI system they’re deploying.)
These three roles aren’t rigid identities. The same person may move across categories depending on their current task, and there’s also genuine overlap between their jobs to be done at times, particularly between builders and domain experts. What matters most is the job to be done at each moment. As AI matures and platforms become more accessible, these distinctions will increasingly blur.
One important distinction: AI consultants and governance leads operate at the system and process level. Their expertise is in how AI should work in the organization, what risks it carries, and how it should be governed. Domain experts, by contrast, hold object-level expertise: they know their field, how work should be done, and how AI can support it. Both groups shape the build, but they need different types of AI explainability.
A Shared Scenario: Configuring an AI Help-Desk Agent
To make the role differences concrete, we use one scenario throughout the sections below: a midsize software company purchases an AI Agent solution so that they can utilize agentic AI for help-desk work. Before the AI agent goes live, the team must configure it; define its scope, test its behavior, and establish guardrails. In this context, explainability is not just an end-user feature; it also helps the people building the system understand what it’s doing and why.
Three roles (AI consultants and governance leads, builders, and domain experts) are involved in configuring and operating this agent. Each interacts with it differently, asks different questions about its behavior, and needs different explanations to move forward with confidence. The sections that follow show what those differences in explainability need to look like in practice.
AI Consultants and Governance Leads
They understand differences between models, how performance varies across use cases, and what enterprise-scale risk looks like. They shape the conditions for good AI use but are not doing the hands-on building or acting on individual outputs day to day. Their primary output is guidance, compliance and review.
For this role, explainability is less about any single decision and more about patterns and risk across the system, over time.
Explanations that Work for AI Consultants and Governance Leads
- Global explanations: how the AI makes decisions across different situations, including overall patterns and known failure modes
- Governance and audit documentation: security posture, edge-case handling, behavior under stress, so they can advise other teams with concrete evidence. This type of documentation can include things like automated-evaluation scores, red-teaming results, and data-access details.
- Audit trails and compliance-ready summaries: support for accountability conversations with leadership and cross functional stakeholders
- Comparisons across deployment contexts: how system behavior changes across use cases, teams, or risk thresholds, particularly when the AI has access to personal information and other sensitive data
- Clear visibility into where human oversight is still needed and where automation can be trusted, to help set appropriate guardrails
According to IBM’s taxonomy of explanations (see sidebar), the explanations appropriate for these roles are global, model-based, and static. These users need a system-level view — trend lines, governance anomalies, behavioral patterns across deployments. A single-instance explanation is rarely enough.
Scenario: AI Consultants and the Help-Desk AI
Before the help-desk AI agent system goes live, the platform-governance lead needs to evaluate whether it’s ready —not just functionally, but also organizationally. She needs to know what the agent is doing when it responds, what data it learned from, whether that training data reflects the organization’s current policies and risk tolerance, when the agent will escalate to a human, and whether that process meets the company’s compliance requirements.
A useful explanation for this role is a pre-deployment audit summary showing topic coverage, handling of edge cases and out-of-scope requests, escalation logic across different issue categories, and where its confidence scores fall below the organization’s acceptable threshold. This role is not reviewing individual answers but instead she needs to evaluate the system’s readiness to operate responsibly at scale. That’s a global explanation.
Builders
Builders work directly with the AI tool to create the AI solution that goes out to end users. Their job includes typical platform-development work (e.g., setting up integrations, adjusting configurations), and also prompt engineering, setting confidence thresholds, running automatic evaluations using LLM as judges, and ongoing maintenance (e.g., LLM-model updates).
Builders don’t need deep knowledge of the model’s internals (e.g., token limits, benchmark scores, architectural tradeoffs), but they do need enough visibility into system behavior to iterate confidently. Many bring deterministic expectations from traditional software development and are still building intuition for AI’s probabilistic behaviors. For them, explanations are a debugging tool as much as a trust signal.
Explanations that Work for Builders
- Local explanations: why a specific output was generated, tied to the inputs and configuration choices that influenced it, including how probabilistic variation in the model may have contributed to the result
- Visibility into inconsistency: where the AI behaves unexpectedly, so builders can identify whether the issue is in the prompt, the data, or the integration
- Interpretable evaluation outputs: what automated evaluation metrics (e.g., low faithfulness score) mean in context and what to do next.
- Change-impact summaries: how configuration changes affect outputs and what tradeoffs need to be made to support faster and more confident iteration
- Actionable error states: failure messages that point toward a solution, not just the problem
- Example-based explanations: how similar inputs produced different outputs, to help builders develop intuition for probabilistic system behavior
The explanation types in IBM’s taxonomy that are most relevant for this role are local, data-based, interactive. Builders operate at the input-output level and need to understand the specific system decisions and behavior in context. Interactive explanations are especially valuable because they let builders ask “What if I changed this?” and build intuition faster.
Scenario: Builders and the Help-Desk AI
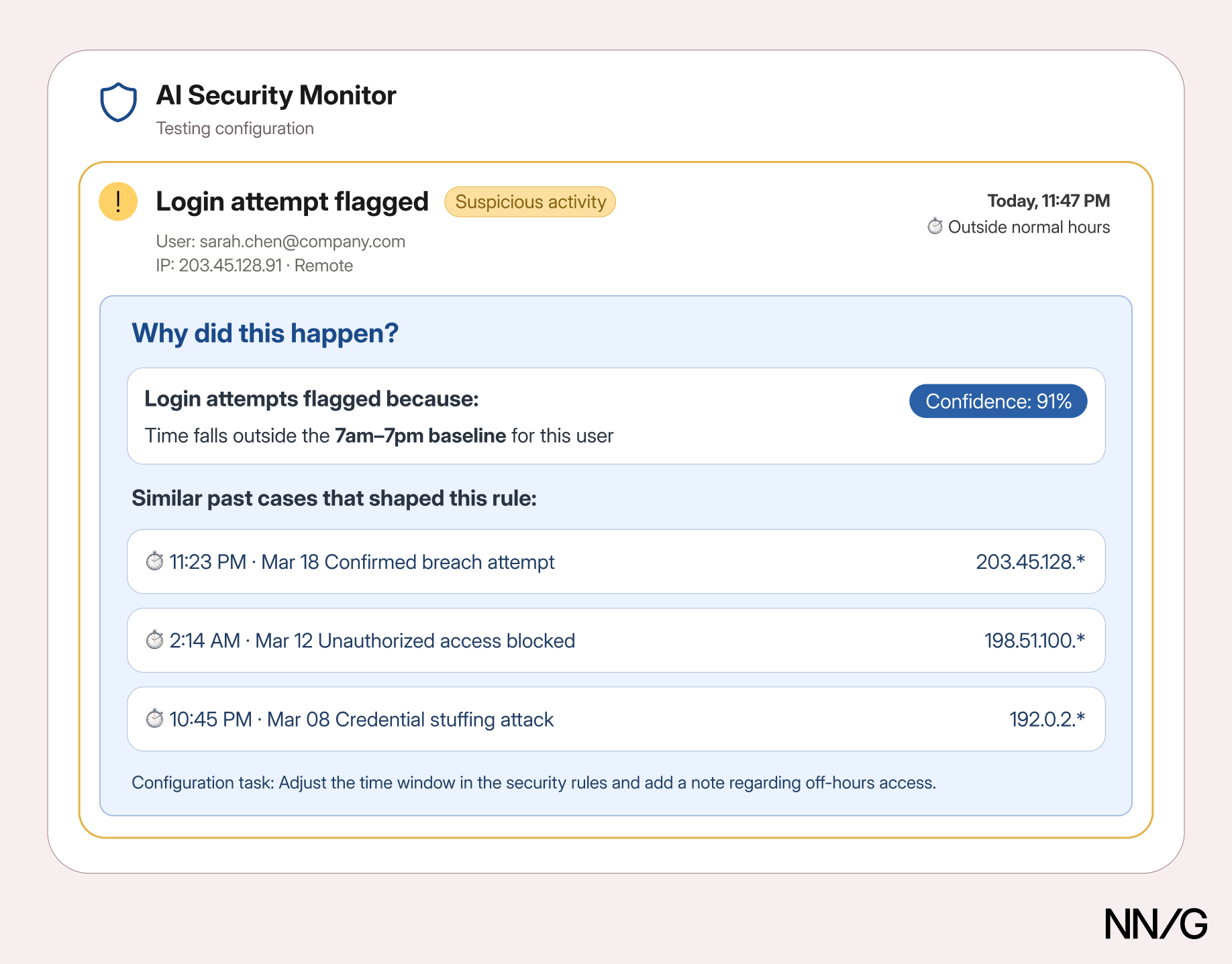
A developer is configuring the help-desk AI agent’s escalation behavior. During testing, she notices that too many password-reset requests are rerouted to a human agent, even though that should be a straightforward self-service flow. She needs to understand whether the issue is in the prompt she wrote, the integration with the identity-management system, or the agent’s confidence threshold for that request type.
A useful explanation for her might say:
This request was escalated because: the user’s account is flagged for multi-factor authentication review, which falls outside the standard password-reset scope defined in your system prompt (confidence: 84%). Similar requests handled by human agents: [3 example logs with resolution paths].
Now she can see exactly where the configuration boundary is being drawn and adjust it by changing either the system-level prompt or the scope definition with confidence.
Domain Experts
This category is broad. It includes those who understand the context AI solution must be integrated into. Their job is to contribute domain knowledge: define the problem, provide key context and data needs, review outputs before deployment, and improve the AI system after deployment.
Domain experts know how to onboard the end users to the AI system and what types of explanations end users need in order to drive adoption.
Unlike builders or governance leads, these users typically don’t need to understand model differences, tokens, latency, or benchmarks. Their expertise is in the policies, workflows, and judgment calls that determine whether an AI output is useful or trustworthy in practice. Their feedback is critical to identifying meaningful use cases, improving performance, and driving adoption by end users.
Domain experts need explanations that help them make the right call faster.
Explanations that Work for Domain Experts
- Plain-language explanations: tied to familiar workflows and free of technical jargon
- Visuals and highlights: surface decision-relevant information without requiring users to interpret underlying data
- Comparisons to similar decisions: grounded in familiar rules and precedents
- Simple flagging mechanisms: to signal when something looks off, without explaining it in technical terms
- Feedback opportunities: ways to correct outputs or contribute domain knowledge that improves future results
- Guidance for surfacing explanations to end users: help shaping AI outputs and explanations to build trust and drive adoption
The explanation types in IBM’s taxonomy that are most relevant for this role are local, data-based, static with embedded feedback. Domain experts need context for a specific output — not how the model works, but what this result means for their situation, compared with cases they recognize.
Scenario: Domain Experts and the Help-Desk AI
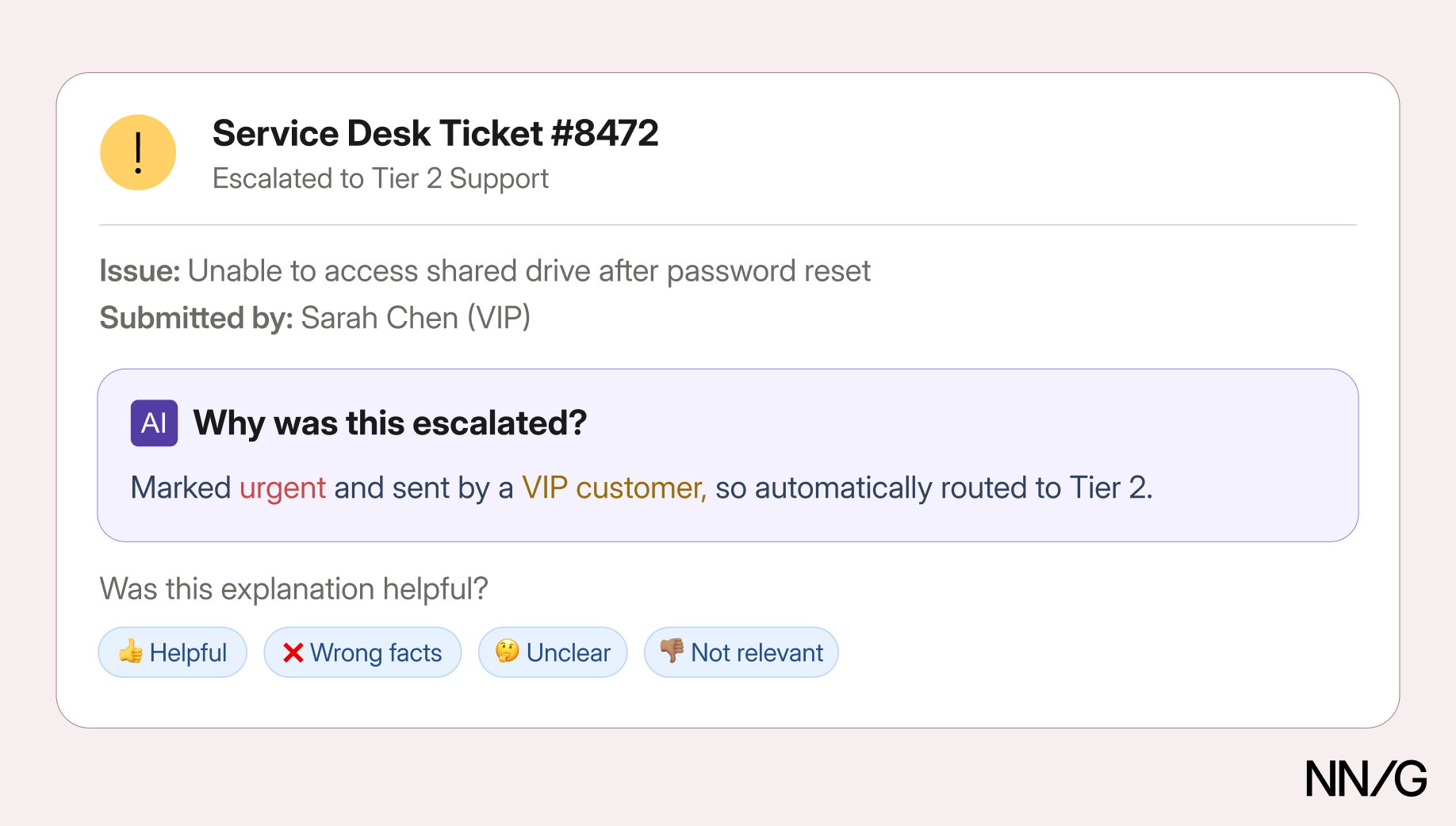
An experienced IT-support specialist reviews a sample of the help-desk AI agent’s test responses before it goes live. Her job isn’t to configure the system — it’s to judge whether its answers are correct, useful, and presented clearly. With eight years of support experience, she knows which edge cases trip people up and which policy interpretations get contested.
When she sees a test response directing a user to a deprecated password-reset page, she needs to know why — not in technical terms, but in a way she can verify, act on, and explain to her team.
A useful explanation for her might say:
This response was based on 14 similar past tickets that directed users to the legacy portal before the migration. The current policy documentation was added 3 weeks ago and may not yet be reflected in the agent’s training data.
The review interface could include a simple feedback widget (Wrong facts / Outdated policy / Unclear to users) that lets her flag problems without writing a technical bug report. Her domain knowledge becomes structured input that the configuration team can use before launch to improve performance.
The Role of Explainability in Fostering Trust
In enterprise AI, trust a prerequisite for adoption, especially when AI systems influence customer outcomes, employee work, or compliance decisions. When users don’t understand why the AI system made a decision, they may override it, ignore it, stop using the system altogether because the reasoning feels too opaque and the stakes are too high.
Explainability is critical and needs to be offered to multiple audiences at once, in a way that is meaningful for each of them. All three roles involved in deploying AI solutions need answers to the same questions:
- Is this decision fair?
- Does it reflect the data I know and trust?
- Can I defend this outcome to my stakeholders?
The answers differ by role. A governance lead needs to know which inputs were weighted most heavily in a prediction. A builder needs to trace a specific output back to a configuration choice. A domain expert needs a plain-language summary and a comparable precedent. There is no single best explanation —only the right explanation for the right user at the right moment. Explainability also builds trust by creating a sense of shared control. When users can question a result, compare alternatives, or test a change, they’re become active participants in the decision-making process rather than passive recipients of AI decisions. That transparency encourages adoption, iteration, and responsible oversight.
This is how collaborative oversight works in practice: different roles can examine the same system through explanations calibrated to their needs and still reach a shared conclusion.
Trust and explainability are inseparable. Calibrated to the right role, moment, and stakes, explainability is how trust gets built and sustained in enterprise AI. And that is where design practitioners come in and play a critical role in ensuring transparency is built in, for all users.
Designing Explainability for Real Enterprise Impact
The framework here is a starting point, not a formula. Real enterprise deployments are messier: roles overlap, systems evolve, and users develop expertise over time. But the principle holds. When explainability is treated as a design problem rather than a technical afterthought, AI systems become not only more transparent, but more useful, more trusted, and more likely to deliver on what organizations actually built them to do.
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not necessarily reflect the official policy or position of ServiceNow or any other organization.