Summary:
Training modern LLMs is a costly process that shapes the model’s outputs and involves unsupervised, supervised, and reinforcement learning.
By this point, you’ve undoubtedly heard that the large language model (LLM) behind your favorite AI tool has been “trained on the whole internet.” To some extent, that’s true, but after training hundreds of UX professionals on how to use AI in their work, it’s clear that many don’t understand how the AI is trained. This is crucial for forming an accurate mental model of how these LLMs work, their limitations, and their capabilities.
This article discusses four basic types of training, when these are performed within an LLM, and how they impact the role of AI in user experience.
1. The Pretraining Phase: Unsupervised Learning
When you’ve heard that large language models have been “trained on the whole internet,” people are typically talking about the pretraining phase, which involves unsupervised learning.
During this phase, the model is fed enormous amounts of text and data scraped from the internet, digitized books, code repositories, and more. One example of such datasets is Common Crawl, which has terabytes of data from billions of webpages. Cleaning these massive datasets before use requires significant effort.
The sheer volume of data makes it impossible for humans to label or explain it all. Instead, the model learns patterns on its own by trying to predict the next word (or “token“) in a sequence.
From exposure to word combinations across billions of examples, the model learns grammar, facts, reasoning abilities (of a sort), and even the biases present in the data.
During the pretraining phase, the AI model is not learning specific tasks or ‘meaning’ in the human sense. It’s pretty much all statistical relationships: which words are most likely to follow other words in different contexts.
Unsupervised Learning Is Like a Toddler
Think of unsupervised learning like a toddler immersed in language for the first two years of life. They hear countless conversations. They aren’t explicitly taught every grammatical rule, but they start absorbing patterns.
Eventually, they begin stringing words together in ways that mimic what they’ve heard, sometimes surprising you with sentences they weren’t directly taught and whose meaning they don’t fully grasp.
Unsupervised Learning for AI-Based Design
While models differ in the types of training data they use, the patterns they learn, and how they rely on these patterns while generating outputs, the principle is the same.
Take Figma AI as an example: for its generative AI features, it needs a large amount of training data as a solid foundation. However, rather than starting from scratch and pretraining a brand new model by feeding it many designs created in Figma (which would have major privacy issues and be extremely costly), they used “third-party, out-of-the-box AI models.” These third-party models call APIs from more robust AI companies, like perhaps OpenAI.
So, how can Figma AI generate user interfaces if it relies on models pretrained on text? Because the pretraining datasets they’re using are so vast, they’ve processed billions of lines of code and learned the patterns in how interfaces are put together. However, this doesn’t guarantee that asking it to “create a dashboard to display recent sales data” will create something useful, accessible, or reasonable. That requires finetuning.
2. The Finetuning Phase: Supervised Learning
If the pretraining phase teaches the model about raw patterns, the finetuning phase (which uses supervised learning) is like giving it specific lessons and examples.
Now, the toddler is older and you’re sending them off to school, where a teacher will give them many examples of correct and incorrect sentences. These carefully selected examples are meant to teach the child how to use the vast vocabulary they acquired during unsupervised learning.
To train AI models, researchers create much smaller datasets containing carefully crafted examples of inputs (prompts) and desired outputs (responses).
For instance, a researcher might write a specific prompt and pair it with an ideal response they want the model to emulate. They might even create several variations of the response and rate them on criteria like helpfulness, clarity, or safety. By showing the model thousands of these carefully crafted examples, they teach it to use the patterns identified during pretraining in useful, truthful ways that are aligned with human expectations. Note that the researchers are still providing all their guidance at input. They are not paying much attention yet to the AI’s outputs.

Supervised-learning datasets are much smaller than those used for unsupervised learning but require significant human effort and cost to create. This phase is crucial for specializing the model and improving its ability to follow instructions.
However, bias can creep in here too. The data used for pretraining already contains societal biases (e.g., due to certain demographics or viewpoints being overrepresented online). During finetuning, the specific examples created and rated by humans also introduce the raters’ perspectives, values, and potential biases.
Different labeling-data teams might instill slightly different “manners” in the model. This is partly why even LLMs that were trained on vast amounts of the same data can have different tones, personalities, and approaches. They’ve been finetuned slightly differently.
Supervised Learning for AI-Based Design
Supervised learning isn’t just for chatbots. Even Figma has finetuned some of its AI features to improve the outputs, though it mentions only features like Visual Search, Asset Search, and Add Interactions — not the text-to-UI features First Draft or AI Prototyping.
Figma’s finetuning used “data from public, free community files” — that is, it relied on freely available designs rather than on high-quality ones created or vetted by Figma employees — a sensible approach that is cheap, quick, and doesn’t violate any privacy restrictions. However, to return to our analogy, the toddler’s “teacher” is using free examples from the internet rather than a curriculum designed by experts.
This does not mean that Figma AI will fail to produce anything useful; it simply means that the outputs are strongly biased toward the patterns available in the free, public files. Don’t be surprised if the outputs feel generic — Figma itself says, “we need to train models that better understand design concepts and patterns.”
Only when AI tools for creating UIs have been carefully finetuned by expert designers will we see as much nuanced power in AI-generated UI design as we currently see in AI-generated language.
3. Advanced Finetuning: Reinforcement Learning with Human Feedback (RLHF)
This final type of training is an advanced fine-tuning technique that relies on human judgment of the model’s outputs. Now the child is doing writing exercises using the vocabulary they’ve absorbed (unsupervised learning) according to the rules and examples they’ve been taught (supervised learning). The teacher provides feedback on the child’s work. Then the child adjusts their process based on the teacher’s immediate feedback.
Reinforcement learning with human feedback is much the same: humans coach the AI model based on its outputs, often guided by how they feel about the outputs when the success criteria are difficult to define. For tasks with clear, reliable success criteria, such as a robotaxi safely navigating to a predetermined destination without crashing, AI models can iteratively learn on their own based on success or failure (often simply called reinforcement learning).
But what happens when success isn’t easily defined by a simple rule, such as the difference between good and bad or useful and not useful?
RLHF brings humans into the loop during the reinforcement-learning process. The model might generate two or more responses to a prompt. A human labeler is then asked to rank these responses — which is better? More helpful? More harmless?
If you’ve ever been presented with multiple versions of a response while using an LLM, you have been involved in RLHF. Gathering this feedback from real users allows AI companies to gather feedback reflecting real user preferences at scale.
It’s important to understand that this human-preference data isn’t used to directly reward or punish the main LLM. Instead, it’s used to train a separate reward model (or preference model).
This reward model learns to predict which kinds of responses humans tend to prefer. Then, the main LLM uses this reward model as a guide, trying to generate responses that the reward model would score highly. Essentially, the reward model learns patterns from the human feedback to create the rules of the game, then scores the main LLM on how well it’s able to play by these rules.
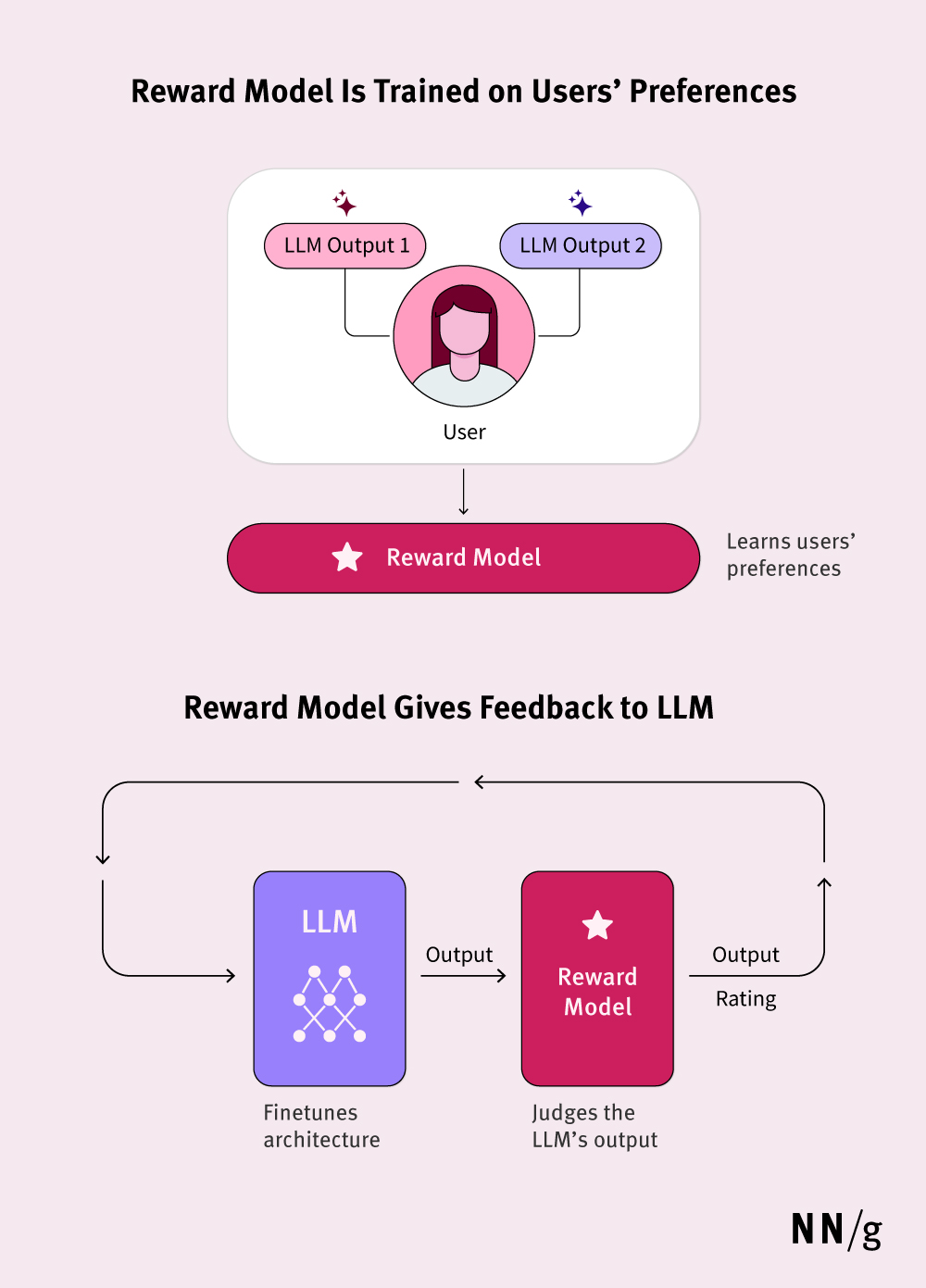
Again, bias is a concern. If the group providing feedback isn’t representative of the diverse user base, its preferences and biases will disproportionately shape the model’s behavior. We know this is still the case because, as with most technologies, the adoption of AI is not equal among all demographics.
RLHF for AI-Based Design
If you are involved in building any user-facing AI products, such as a chatbot on your website, or an interactive voice-response system for customer-support calls, RLHF is absolutely critical for ensuring that the model is giving users useful responses. Yes, through unsupervised learning, you can train such a system to understand your company’s products and services, and through supervised learning, you can give it good examples of responses, but you are not the user. Your team can only provide so much feedback to the model regarding what it ought to say. You must also account for the reactions of the real users interacting with the product to help refine its responses over time.
External vendors selling these types of services, or teams building them in-house, need to plan for some form of reward model that can continue to finetune responses based on what real users think about the outputs.
LLMs Differ from Search Engines
This is one of the places I see UX practitioners getting the most confused.
Search Engines Retrieve Existing Information
When you enter a query, a search engine searches its indexed database of web pages and documents to find and rank the most relevant existing content. Then it points you to those sources. If there is nothing in the database, it can’t give you a response.
Large Language Models Generate New Information
When you give an LLM a prompt, it uses the statistical patterns learned during training to predict the sequence of words most likely to form a relevant response. It’s constructing the answer word by word based on probabilities, not retrieving a prewritten answer from a database.
This generative nature is why LLMs can hallucinate — confidently state incorrect information. Their primary goal is to generate a plausible-sounding sequence of words relevant to the prompt, not necessarily to state the verified truth found in their training data (which might contain errors). While some newer AI tools integrate search results (through a technique called retrieval-augmented generation or RAG) to pull in real-time information before generating an answer, the core LLM response is still generated, not retrieved.
Environmental and Labor Costs
Training and running AI models come with significant costs:
- Environmental cost. Training large models via unsupervised learning requires immense computational power. It involves running thousands of specialized processors for weeks or months, consuming substantial amounts of electricity, and contributing to carbon emissions. Even running the model for users like you and me consumes energy, especially at the scale these services operate.
- Labor cost. While unsupervised learning does not rely on direct human labeling, reinforcement learning with human feedback and at least some types of supervised learning depend heavily on human work. Thousands of people around the world are employed to create training examples, write prompts, rate model responses, and check for harmful content. This data-labeling work is often outsourced, sometimes low-paid, and can involve exposure to sensitive or problematic content, raising ethical considerations about the conditions and compensation for this crucial human-intelligence work powering the AI.