A little more than two decades ago, the young web had a very big problem: Finding the “right” information and what you needed was very hard. In other words, back then, search engines sucked.
And then came Google, with a single purpose, to show people what they need, when they need it. It was not an easy task as it involves two major parts:
First, you have to truly understand what people want when they use the search tools (not what they type in the search box, but what they “desire” to see as the result) and second, what results should come first, or in other words, “who” among the many relatively similar sources, has the right answer.
And then for a long time, the problem seemed to be (almost) solved. People were continually more content with results that they received from Google and websites learned and learned again how to play with Google rules & algorithms. Then social networks rose and changed the game.
To be honest, social networks never truly shared the vision of showing people what they need, when they need it. They ultimately target the engagement of their users or for lack of a better word, the addiction of their audience. Search engines try to push people away from their platform as soon as possible and social networks want to lock people in themselves, as long as possible. So for them, the network effect and the interaction of the users are far more important than the content.
Therefore, they never truly cracked search engines in their core. Every “Explore” or search function in every social network reminds people of the crappy search engines of the 90s. Nobody can find what they’re looking for and nobody knows which result to choose.
Social networks ignored two major parts of what Google did for the web: The understanding of their users’ “desire” when they use the search, and the ranking of results. On top of that, something much worse happened to them: Since it is so easy to automate everything in a social network, fake accounts, automatic accounts, and “bots” took over the majority of almost every social network in the world, despite all the efforts.
Social network accounts are much easier to create than websites, they are easier to be duplicated, engaged, and automated. They have far less responsibility and accountability, so misinformation & fake information flows in them much faster under the radar, using the network effect to its advantage.
Why should we care?
Twitter suffers from this disease particularly. People around the world use Twitter more than any other social network to follow the news, get updates, and basically stay informed. After all these years, Twitter showed that it’s unable to solve this problem on its own. (Check this study from the University of Iowa to see the depth of the problem)
Today, the biggest problem with Twitter is fake information and fake accounts. There are millions of bot/fake accounts on Twitter that are tweeting and retweeting fake news and irrelevant data. This situation is causing the real news and the real information to be buried under the avalanche of fake information.
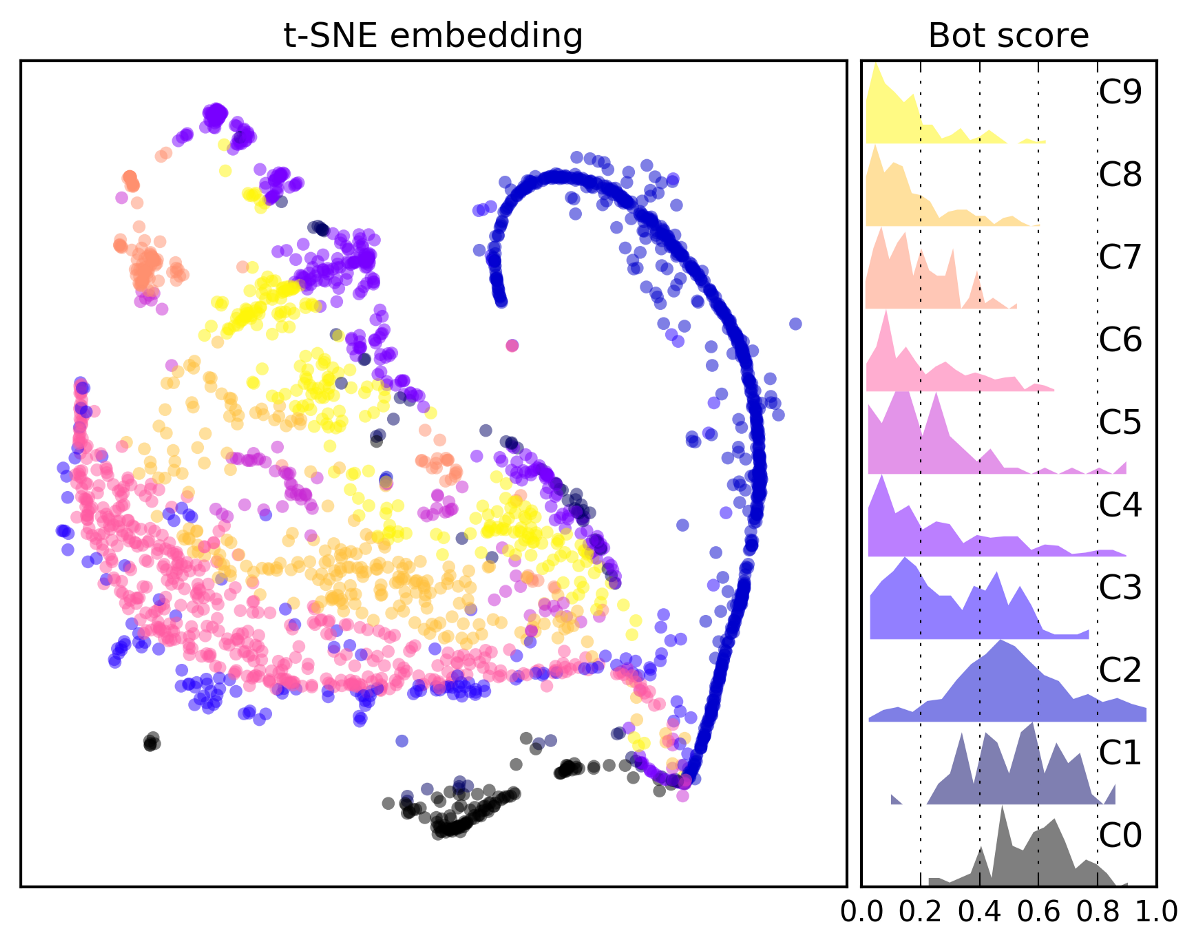
For example, this study in 2017 reveals that a significant fraction of Twitter accounts, between 9% and 15%, are likely social bots. This translates into nearly 50 million accounts, according to 2017 estimates that put the Twitter userbase at above 320 million, and today it’s more than 500 million. Although not all bots are dangerous, many are used for malicious purposes. You can see the analyzed interactions between humans & bots in the picture above.
To solve this problem within Twitter, we should bring what made Google great, into Twitter. Twitter should have a ranking system for all accounts and content within its platform. To have a perfect ranking system, we have to think like a search engine, to connect the “desire” to the “right answer”.
Analyzing billions and billions of Twitter datasets will take forever and will not produce the results we want. Once again, we borrow a page from Google on how they’re ranking every website and their content in the world without analyzing everything within them.
Actions & Interactions Method
To start, we used the actions and interactions method for our data analytics. This method focus on “what’s happening” rather than analyzing the whole dataset. This method is especially useful in social networks or in scenarios that the whole data isn’t available or is too big to analyze.
The actions of every Twitter account will create a pattern of their activities. These patterns, when compared in large numbers, create various segmentations. In simple words, we can understand what is every Twitter account, is it a business account? A normal user? A news listener? A dog person? A democrat? A foodie?… You get the picture.
This isn’t enough. Various segmentation means different groups, overlapping groups, and anomalies. More important than actions, are interactions.
Analyzing interactions of Twitter accounts shows the “quality” & “impact” of every account. Is this an automated account? Is this account influential to others? Is it a fake account? Is this account working in an organized group of accounts (organized accounts to empower each other, e.g. elections manipulations)?
The ultimate question that combining these two methods answers is this: Should I follow this account? Is it trustworthy or not?
How does Rank for Twitter work?
We used Twitter Public API as our data source and the aforementioned “action & interaction” method as our method of data analytics. We used Formaloo as the data platform to execute our algorithm.
For testing the algorithm, we published a very simple android application so everyone can test it for themselves. You can download it here from Google Play.
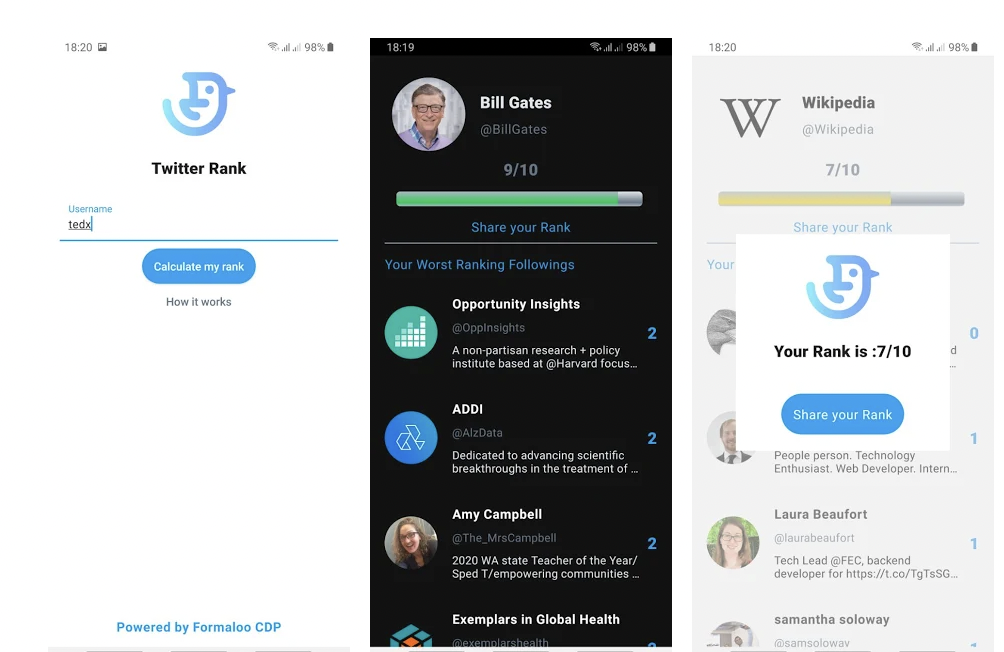
This app aims to analyze every Twitter account and rank them based on their activities, interactions between users, and the content that they’re sharing. These ranks are calculated between 0 and 10, with 0 being the lowest score possible (mostly associated with fake accounts, bots, or inactive accounts) and 10 in the highest score possible. All ranks will be updated monthly.
Twitter Rank works by counting the “number” and “quality” of interactions to a Twitter account to determine a rough estimate of how important the account is. The underlying assumption is that more important accounts are likely to receive more “real” interactions from other Twitter accounts.
This algorithm helps Twitter and Twitter users to identify which accounts are real & impactful and which accounts are inactive, fake, automated, or act suspiciously. With this app and this algorithm, we try for you to see the real value behind every account that you’re following and decide to get your information with insight.
This proposed algorithm is very young and full of inaccuracies but with enough testing and the power of crowdsourcing, it can provide the most reliable ranking system that Twitter needs.
The social networks we deserve
Social networks today, are not the social networks we deserve, just like search engines, quality is way more important than quantity. It’s not enough to create better and better recommendation systems in search functions of social networks. We need to implement the perfect ranking system for the search functions as well.
It’s not enough to focus on engagement, which leads to addiction and later on, loathing of the same network. People have different desires, one after another, that should be answered & satisfied, every time.

![]()
The big flaw of social networks, and how to solve it was originally published in UX Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.