A while ago I still had parentish questions like “am I a good designer if I don’t test for all my interfaces?”, “is it OK that I postpone problems that faced only one of four respondents?”, “how many users to involve for unmoderated sessions?”, etc. Thanks to Nielsen, Lewes, Virzi and some other sirs, who put this questions in math perspective. It helps to find objective basis to answer them with decent level of certainty.
This text is a summary of math perspective for two sides of testing in design: how many respondents to invite depending on specific goal and how to interpret findings. You supposed to be ready to read about formulas, probability and confidence interval. Close it otherwise.
It isn’t aimed to have general answers. Some of them are in other great articles. From Jeff Sauro and Jakob Nielsen about why you need only 5 users for usability testing, and another one from Jeff Sauro about accuracy of testing results.
I intentionally don’t use ‘usability’ for ‘testing’ as I believe logic applies to other research practices.
Probability
Testing is a situation with two possible outcomes. Respondent will face or won’t face a problem. Like tossing a coin, but with probability which can be different than 50/50. In statistics probability of one result from two options is called binomial. Original formula of binomial probability is:

It describes probability ‘P’ of getting result with probability ‘p’ exactly ‘k’ times in ’N’ number of tries. Initially in this formula we could consider ‘P’ and ‘k’ as defined.
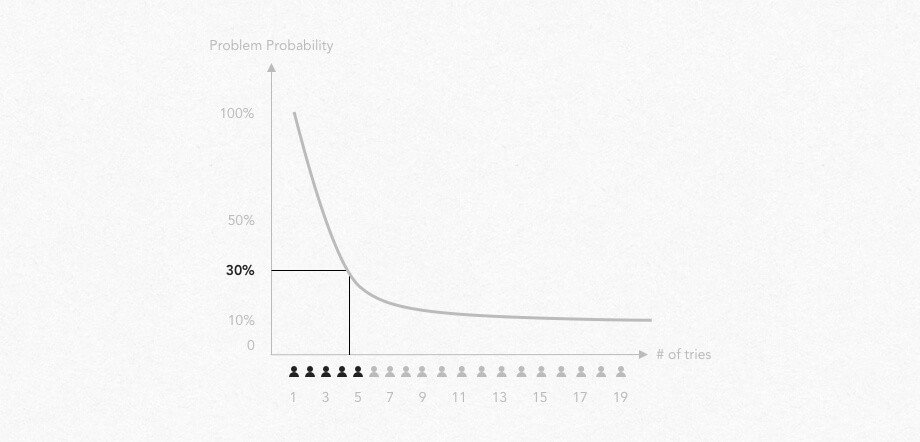
To have decent level of certainty we want to have probability of facing a problem ‘P’ around 85%. ‘k’ is number of time we want to face an issue and basically it is at least 1 or more.
So, out of [P, N, k, p and q] we basically don’t know only number or tries (N), which has inverse relationship to problem probability (p). Thats how formula and its graph looks for our testing now:

Basically, the less probable problems we are aiming to, the more people we have to involve in testing.
Big input from Virzi and Nielsen was that based on data research they defined ‘p’ for usability testing. According to them, average probability to find usability issue is approximately 0.3. So, on average we need to involve 5 respondents to be 85% sure we’ve faced each 30% probable issues on users way. Or that we faced 85% of such issues.

For design testing, number of respondents you need depend on project situation= problems probability. E.g. in concept prototype we likely need to find architecture and UI problems which have high probability.
One thing to keep in mind that calculations above a for facing problem at least once. You may read a bit more about binomial probability calculation, and about cumulative distribution.
Confidence Interval
Let’s look at testing result probability from another side. What is probability to face a problem if we faced it once in five test session? Like in our testing session from probability section. 1/5=20%? 🤔
Confidence interval tells ‘from’ and ‘to’ what percentage may be probability of that issue. Formula of binomial confidence interval for 95% of certainty is:

In short:
- if you have 5 respondents confidence interval is about 35%. In other words, if you faced 1 bug out of 5 tests default assumption is that rate of a bug is 20%. But due to confidence level 35% it is fair to assume that a bug still can have probability rate between 1% to 55%;
- if you have 20 respondents confidence interval is about 17.5%;
- if you have 100 respondents confidence interval is about 8%;
- if you have 200 respondents confidence interval is about 5.5%;
Even if you faced issue just once for 5 respondents — there is a good chance it is a one for about 20(±30)% of respondents. Consider it as serious as other issues you faced more times.
Besides, confidence interval tells how many respondents to have for summative tests if you need particular level of results certainty.
Read more about confidence intervals here or here.
In short, how many [respondents]? 3 to 5 respondents is optimal for one run of usability testing on average or to find ‘big’ problems. For significantly different groups of users — do testing for that groups separately, inviting less respondents per each. For unmoderated sessions it depends on level of needed certainty, but between 100–200 respondents seem sufficient for regular cases.
Testing, its way and scale ultimately depends on level of issues you are aiming to. Before testing we need to define level/probability of issues we are aiming to find. E.g. it is not effective to run unmoderated testing sessions with 200 people for product concept, where we are aiming on architectural or conceptual problems. It is hardly so to run 3-people guerrilla testing for quite common-looking LP which had few A/B testings. Products or interfaces have different goals at moments of time and supposed to use appropriate methods.
I tested with five people and consider only issues which faced at least two of them. Issues of one might be personal, insignificant or even a mistake. Riiight? Not exactly. As stated above that might be an issue actual for 1–55% of people. Ultimately with small number of respondents we should consider all issues seriously. When decide what to issues to fix, consider level of influence on conversion or a flow completion.
No, we don’t need to do in-person usability testing for all interfaces. No, if that is something typical or we don’t seriously anticipate >50% of people have problems with that UI. Better setup analytics or try test different versions with A/B tests. One another exception is if we do creative concept and ‘different’ experience is in priority.
Should we do user testing for a new product? Absolutely. But try to start with few sessions of rough usability testings with 3–5 people. The most important thing for new product is to validate architecture and unfamiliar functionality of a main flows.
We have developed product with solid userbase, should we test it? Yes and no. That probably wouldn’t be usability testing with 5 respondents. If you decide that it worth it, that might be usability testing for 10–20 respondents. As for more or less polished interface we’d be aiming on issues actual for 10–20% of people. Another idea is to run testing it with particularly vulnerable group of users. That might help to lower number of required people.
We want to make user testing, but our partners insist on heuristics analysis. What difference in results of different methods? Hertzum and Jacobsen didn’t find significant differences in results of different methods. “Across a review of 11 studies, they found the average agreement between any two evaluators of the same system ranged from 5% to 65%, with no usability evaluation method (cognitive walkthroughs, heuristic evaluations, or think-aloud user studies) consistently more effective than another”. It brings another interesting known issue with validations that if we give a product for testing to different evaluators we will get very much different results. They say it’s OK)
How we test UI or part of a product where mistakes are dangerous or significantly influence product success? Facilitate usability testings with 10–20 respondents or apply quantitative methods, like unmoderated testing.
I want to make quick and dirty paper UI prototype and test my product. What it will help me with? Do it. It will help to find architectural issues. But if you mind — make it again when have Visual Design. It makes a big difference on UI interaction level.
We can extrapolate binomial probabilities logic to other research practices. E.g. if we make research with in-depth interview we can apply the same logic with probability of facing product or service experience problems. If we made 5 interviews — we are 85% sure we talked to people, who faced about 30% of possible problems. However, things are a bit more complicated with research. In example of interviews we talk about experience which happed before, we cannot observe or moderate it and we deal with opinion.
Probability may be measured and testing sample size may be scaled dynamically. Read more about it here.
Testing makes difference by itself. Building prototype for testing lead designer to missed cases and UI states. It is helpful by forcing designer to walk through each step of a flow and giving other perspectives. In design of new experience or functionality, testing helps designer get out of a shell by talking to other people.
Usability testing should be conducted correctly. All of the above is valid for solid testing methodology. If researcher led one respondent to an issue or just felt that there was something wrong with finding a button — its different science.