There are several firewall applications for Linux, but what you may not realize is that, at the heart of all these programs is a single all-mighty application that is built right into the Linux Kernel: iptables. This is the Linux firewall. No matter which program you use to configure your firewall under Linux, it ultimately all comes down to iptables. All that these other programs do is configure it.
So, here comes the question: if those programs simply configure iptables, why not simply configure it directly yourself? Doing so is easier than you might think!
Networking Background
If you’re familiar with networking terms, like connections, IP, TCP, and Port, then feel free to skip ahead to the next step. Otherwise, if you’re new to networking, read on to familiarize yourself with the terms that you will need to understand, in order to follow along with this tutorial.
Please note that the terms and definitions below have been intentionally over-simplified. They’re meant for every-day users, not sysadmins. So if you are a seasoned sysadmin or you have a CCNA in you pocket, please excuse me for not entering into the details.
TCP/IP
TCP/IP is a protocol that allows computers to communicate with one another over Internet and Ethernet Networks.
Failure is the last resort.
Imagine an Ethernet Network as a small local network (LAN – local area network), like your home PC, laptop, and smart phone. It’s a small heterogeneous network that is isolated from the rest of the world. A network of such networks is what we all know as the Internet: a set of interconnected networks.
TCP/IP is a combination of two protocols working at different levels in the hierarchy of the network communication chain. We won’t delve into details about that hierarchy. TCP stands for Transfer Control Protocol, and its core responsibility is to ensure that communication is successful. It controls the correctness of the data sent, and ensures its success. It has different algorithms to perform sophisticated checksums, autocorrect, and retry. Failure is the last resort. The name, IP comes from Internet Protocol. You can best associate it with the “phone-number” of your PC. Each machine capable of communicating over the Internet must have an IP address – a unique phone number – so that communication packets can find their destinations. A packet is a small piece of data inside a communication stream, which is self contained and can be checked for correctness. Essentially, we can say that our computers send TCP packets over the Internet using the IP protocol.
Each network communication is bound to a specific port. Network ports range from 0 to 2^16 (65536). Each network connection has an outgoing port for the one who initiates it, and an inbound port for the one who is listening for other computers’ messages. There can be several connections between several computers over identical ports. A computer can, however, talk over several ports at once. So, basically, ports are good to identify services and define channels of communications, but they do not limit the amount of data or connections.
Some computers can have similar IP addresses. You may have observed that both your computer at home and at work have IP addresses that takes the form of something along the lines of 192.168.something.something, or 10.0.something.something, or 172.16.something.something. These are the so-called private IP addresses that can be used only inside your LAN. You can’t go out to the Internet with IP addresses like this. They are akin to interior numbers for your company’s phone network.
Gateway & Bridge
A Bridge is what computers with real (public) IP addresses pass to the Internet.
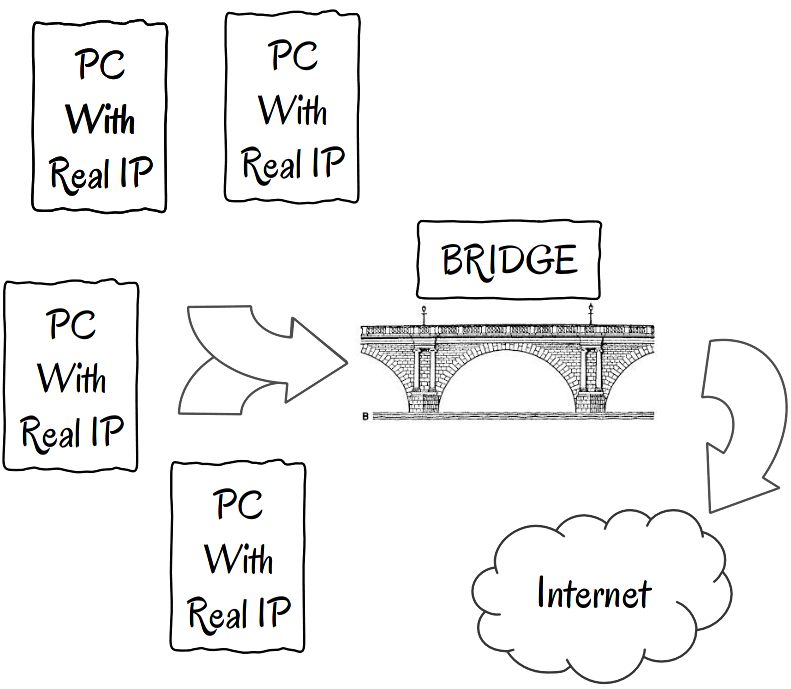
Essentially, these computers have the rights and capabilities to talk to one another on the Internet directly. But, since there are no direct connections between all the computers in the world (that would be quite hard to accomplish), bridges are responsible for connecting segments of the Internet.
Keeping our telephony analogy alive, you can imagine these bridges to be similar to the telephone centers in your town or neighborhood. If you make a call to another local number (the computers on the left in our schema), the communication could have been made directly by your telephone center by physically connecting your line with you neighbor’s. However, if you instead want to call your distant uncle Bob, your call would have to be redirected over several phone centers until your uncle’s phone could be connected. These form a bridge between your town and his town.
A Gateway is a way for computers from a private network (LAN with private IP addresses) to communicate with other computers on the Internet.
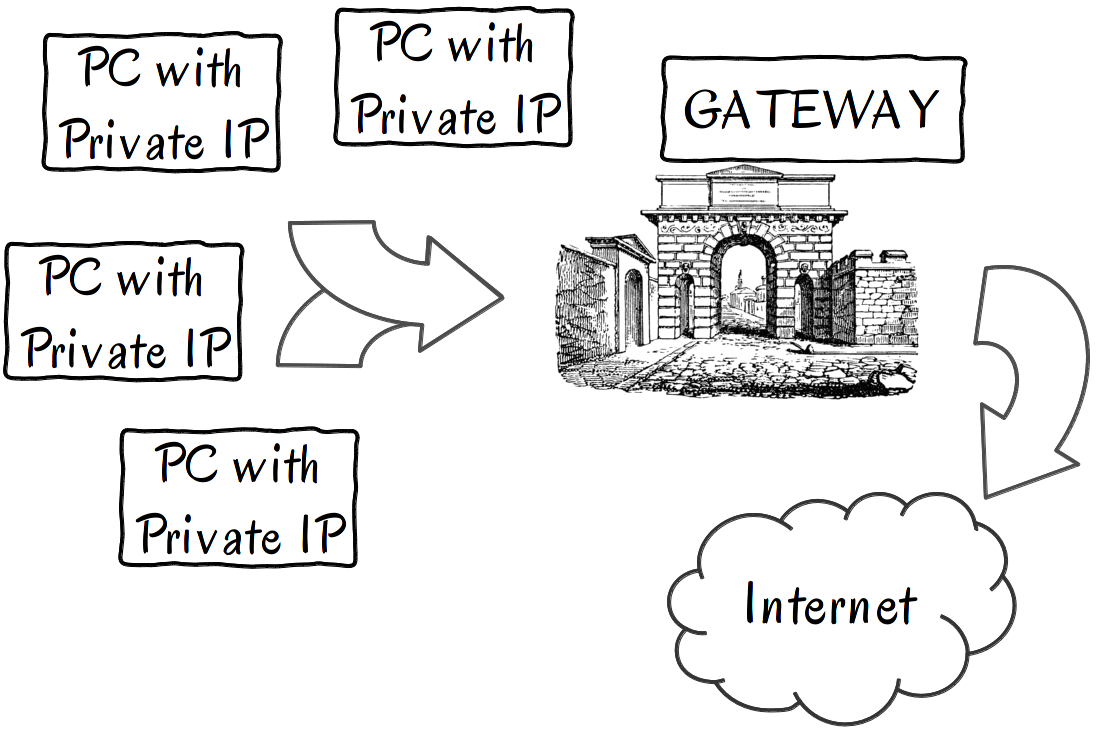
A private network is like your company’s private phone network. You can call interior numbers, but in order to call someone who is outside of your company’s network – like your wife at home – you must first dial a special number or prefix.
Computers actually function in a similar way. When you are on a private network, you have a so-called gateway computer. When your computer attempts to talk to another computer on the Internet, it will automagically contact the gateway first and request “a line” to the outside world. The gateway will do the talking to the computer found on the Internet, and will forward the message back to your computer. You, as an ordinary user, see no difference between a bridge and a gateway. Your computer will know how to deal with them.
Definition of a Firewall
A firewall is a program running on a Gateway, Bridge or PC/Laptop/Smartphone that is capable of filtering incoming, outgoing, and forwarded network packets. A firewall is essentially a tool that lets you restrict you or your network’s access to the Internet, and someone else’s access from the Internet to your network.
And yes, your cable router or home Wi-Fi is, in fact, a firewall for all your computers and gadgets that connect to the internet through it.
The Problem We Will Solve
To set the context, let’s imagine a very possible network architecture. I’ve seen many small companies running something similar to this.
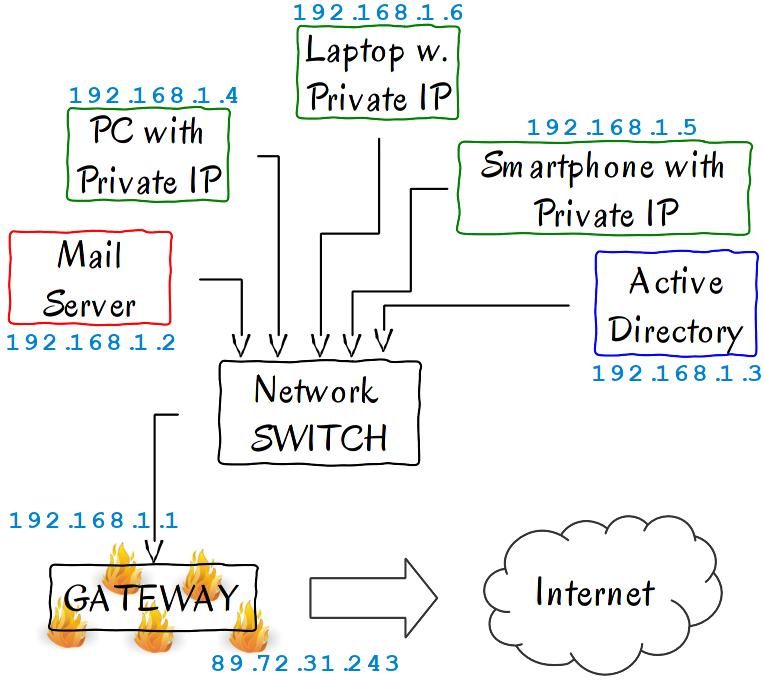
What we have here is actually something quite simple:
- A few computers and other network-connected devices – the green boxes
- An e-mail server – the red box
- A Microsoft Active Directory server – the blue box
- A gateway, which is also a firewall, for our network running Linux – the black box
- Between all of these is a simple network switch
In the following section, we will configure iptables on that gateway, so that it will allow all the devices in the network to connect to the Internet. It will allow us to connect to it, via SSH, and will allow external mail servers to reach the mail server inside our network – a computer that does not even have a public IP address; only a private one.
Iptables Components
Iptables’ name actually has a meaning in its functionality. It’s a set of tables of IP address and ports with some actions attached to them. In iptable’s terms, these tables are referred to as chains. An unconfigured, empty iptables might look like this:
csaba ~ # iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
You can observe that there are three main chains:
- INPUT – all incoming connections
- FORWARD – connections passing through
- OUTPUT – connections departing from this server
The term, “policy ACCEPT” in parenthesis means that ACCEPT is set as the default policy for that particular chain. So, when there is no match for a connection, that rule will be applied. There are three main concepts you can use when configuring your firewall:
- default policy ACCEPT & deny selectively all you need to – it may be difficult to specify all that it is denied. I do not recommend this approach.
- default policy DROP or REJECT & allow selectively all you need to – this is better, but it has a problem. If you make a mistake in your iptables configuration, you can easily remain with empty chains denying access to everything and everyone, including you. So, unless you always have physical access to your firewall server/computer, I recommend that you use the next approach.
- default policy ACCEPT & an explicit policy to DROP all & then allow selectively all you need – this is a combined solution between the first two possibilities. It will use an ACCEPT default policy, so if something goes wrong, you can log back over SSH or whatever remote connection you use for your firewall. At the same time, an explicit DROP rule for any unmatched connections ensures that you are safe. Allowing only what you know about and actually need to use offers the best possible protection.
Adding Rules to Iptables
There are two ways to add a new rule to iptables. One is to insert it at the begining of a chain. The other option is to append it to the end of a chain. Why does it matter in which order the rules occur?
Important: iptables check the rules in a chain from top to bottom. It will stop its search at the first match.
You must design your rules in such a way to consider the above mentioned behavior of iptables. After the first match of a rule, iptables will take the actions specified by the rule, and then cease the search. If no rule matches the connection that is checked, the default policy applies.
Inserting a New Rule
Let’s say that we want to add a rule to our iptables that will allow anyone to connect to port 22 on our firewall. Port 22 is the port for the SSH protocol. Of course, a good server admin will change this port to something unexpected for obvious security/obscurity reasons, but that’s another story for another tutorial. We will stick with 22.
csaba ~ # iptables -I INPUT -i eth0 -p tcp --dport 22 -j ACCEPT csaba ~ # iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT tcp -- anywhere anywhere tcp dpt:ssh
I presumed that the IP address facing the Internet with the public IP on it is on the network interface, called eth0. Let’s dissect this command:
- –I – stands for insert the rule
- INPUT – specifies the desired chain
- -i – stands for network interface – in our case,
eth0 - -p – is for protocol (tcp or udp)
- –dport 22 – is for destination port 22 – it has a corresponding
--sportversion for source port verification - -j – actually comes from “jump,” and is followed by an action -in our case, the action to accept the connection
However, you may have already guessed that this rule has little effect at this time. Our default policy is ACCEPT, so accepting something explicitly does not offer us any extra functionality. Now, remember the third recommended way to set up our firewall: the explicit rule to deny everything not matched. Let’s add that rule.
Appending Rules
We want to append a rule that blocks incoming traffic. But be careful: we only want to block what could be harmful. If we block everything, we will not be able to do anything, because the replies to our requests will be rejected. For example, when you browse a web page, you make a request, then you receive an answer. This answer comes into your computer, so, on the INPUT chain, we must have a rule to allow it.
First, we will append a rule to accept incoming traffic for already established connections, such as responses to requests.
csaba ~ # iptables -A INPUT -i eth0 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT csaba ~ # iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT tcp -- anywhere anywhere tcp dpt:ssh ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
Now that we’ve safeguarded our existing connections and the replies to the connections we initiated, we can deny everything else that wasn’t matched.
csaba ~ # iptables -A INPUT -i eth0 -p tcp -j DROP csaba ~ # iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination ACCEPT tcp -- anywhere anywhere tcp dpt:ssh ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED DROP tcp -- anywhere anywhere
We’ve appended another line, with a rule to DROP all connections that match. Remember: this rule will only apply if none of the previous ones actually match.
There are two ways to refuse a connections.
- You can use DROP, which is equivalent to dialing a non-existent phone number with the difference that, after some time, the network connection times out. With a phone number, a robot informs you that the number does not exist. But the end result from the point of view of the caller is the same: it thinks that the destination does not exist.
- The second way to refuse the connection is with the rule, REJECT, and an optional message. This is analogous to the number you are trying to call being busy. You may know that there is a number, you know it can be called, but it simply refuses to take your calls. Optionally, you can provide a message with a REJECT rule; the default is “ICMP port unreachable” or something similar.
Allow Computers to Access the Internet
At this point, we have some basic rules for the INPUT chain. But we have a network of computers having private IP addresses. We need to provide a gateway to the Internet. This is also done by iptables: the firewall.
Network Address Translation (NAT)
Likely, you’ve already heard this term: NAT. This refers to the procedure of translating one network address to another and forwarding the information between the two. It’s most frequently used in architectures like our own. The gateway has to do NAT in order to translate any computer’s IP from the LAN into its own public IP and then back.
Routing is the procedure by which a system can figure out on what network interfaces and toward what gateway it can communicate to reach its destination. Each computer has a routing table of its own to determine this. Iptables can hook into this routing procedure at two different points: before and after the procedure has occurred.
Nating with Iptables
csaba ~ # iptables -t nat -A POSTROUTING -o eth0 -j SNAT --to-source 89.72.31.243
This command adds a rule as POSTROUTING to the NATing table (-t nat). POSTROUTING essentially means that the packets first pass the routing mechanism on the gateway, and, only after that are they modified. The rule -j SNAT means Source NAT; the source address of the packets will be changed to the address on the interface specified by -o eth0 – in our case, to the IP address specified by the option, --to-source. So, anyone contacted by a computer in your network will assume that it is talking directly to your gateway. It will have absolutely no clue about the fact that the packets are destined for some different computer. The gateway, using iptables, will keep an internal list of all the translated IP addresses, and, when a reply comes, it will revert the change and pass the answer to the computer inside the network.
Allow Client from the Internet to the Email Server
Another problem that we face is what to do when we have a server that is behind a firewall. We need to allow the clients, coming from the Internet, to communicate with our server in some way. This is the case with our mail server. When an email arrives that has to be delivered to a mail account on our server, the sending email server will have to connect to our receiving one.
But our mail server only has a private IP address. There is no way that an external computer could connect to it directly. On the other hand, our gateway has an external IP that anyone could connect to. The solution? Open a port on our gateway so that a request from the Internet to that port will actually go to our email server. The answer, of course, will travel through the gateway back to the client. The trick is to use a different type of NAT here, called Destination NAT. This changes the packets destination and then reverts them back when the response occurs. Think of DNAT as the reverse of SNAT.
Tip: You may know this feature as “Virtual Server,” if you’ve ever played around with small home routers.
csaba ~ # iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 25 -j DNAT --to-destination 192.168.1.2:25
So, what is happening here? A packet comes in to our gateway at the port 25 (the port used for SMTP, the email protocol the whole Internet uses). The rule above catches this packet because of the --dport 25 option, which basically says, “Match anything that goes to this port on the interface specified by -i eth0. Now that the packet is matched, change its destination from the current machine (the gateway) to the one specified by --to-destination.” Please note that you can specify the port explicitly after the IP address by separating it with a colon.
Finally, note that this is in the PREROUTING hook. The destination has to be changed before the routing actually takes place. Otherwise, the packets would end up on the gateway and find no way to the mail server.
Persisting iptables Configuration
The rules you insert or append to iptables are in memory. After a reboot, spoof: everything is gone! To save your configuration, you should dump it into a file, like so:
csaba ~ # iptables-save > /some/directory/my_rules.fw
The file’s name doesn’t matter, nor does its extension. To restore the rules, run this command when your computer starts.
iptables-restor < /some/directory/my_rules.fw
If you take a look at the saved content, you’ll see that they’re the same parameters that we used with the iptables commands. There are some minor differences, but you can easily understand the saved file, and could even write your own such files by hand and load them.
Final Thoughts
In closing, here are some thoughts on when and when not to use a firewall with a Linux computer.
Use a firewall on Linux when you configure a server (like a gateway in our example), or when you have a computer with important information on it that is directly exposed to the Internet. Before you jump on to configure your iptables, consider the potential danger. Ask yourself: is my computer known on the Internet? There are a few billion computers out there. If yours is just one, the chance of being targeted is incredibly low. Are there people directly interested in your information? Hackers don’t waste time stealing random data in the hopes that they might find something. They usually know what they are looking for, and then target the computers containing the desired information. Of course, there are countless attacks against random computers that attempt to install some kind of worm or virus, but on Linux, you are immune by design.
Don’t waste your time with configuring a firewall on Linux when it is a computer that is alway behind a firewall, such as your home PC behind your home router, or when you have no particularly important information on your laptop. If you keep the services that listen on the network to a minimum and have a decently secure password, you can forget your firewall. I personally have no personal computer, laptop or smartphone with a firewall running. I have, however, a home router with a well-configured firewall.
I think you can safely apply these ideas to Mac OSX as well. If you’re a Windows user, sorry: a firewall is your first line of defense. For Linux or MacOSX, though, a firewall is your last line of defense. A carefully selected password and not running useless services should handle the bulk of your computer’s protection.
Thanks for reading. Questions?