Machine learning is the act of giving computers the ability to learn without explicitly programming them. This is done by giving data to computers and having them transform the data into decision models which are then used for future predictions.
In this tutorial, we will talk about machine learning and some of the fundamental concepts required to get started with machine learning. We will also devise a few Python examples to predict certain elements or events.
Introduction to Machine Learning
Machine learning is a type of technology that aims to learn from experience. For example, as a human, you can learn how to play chess simply by observing other people playing chess. In the same way, computers are programmed by providing them with data from which they learn and are then able to predict future elements or conditions.
Let’s say, for instance, that you want to write a program that can tell whether a certain type of fruit is an orange or a lemon. You might find it easy to write such a program and it will give the required results, but you might also find that the program doesn’t work effectively for large datasets. This is where machine learning comes into play.
There are various steps involved in machine learning:
- collection of data
- filtering of data
- analysis of data
- algorithm training
- testing of the algorithm
- using the algorithm for future predictions
Machine learning uses different kinds of algorithms to find patterns, and these algorithms are classified into two groups:
- supervised learning
- unsupervised learning
Supervised Learning
Supervised learning is the science of training a computer to recognize elements by giving it sample data. The computer then learns from it and can predict future datasets based on the learned data.
For example, you can train a computer to filter out spam messages based on past information.
Supervised learning has been used in many applications, e.g. Facebook, to search images based on a certain description. You can now search images on Facebook with words that describe the contents of the photo. Since the social networking site already has a database of captioned images, it can search and match the description to features from photos with some degree of accuracy.
There are only two steps involved in supervised learning:
Some of the supervised learning algorithms include:
- decision trees
- support vector machines
- naive Bayes
- k-nearest neighbor
- linear regression
Machine Learning With the Sklearn Library
Sklearn is a machine learning library for the Python programming language with a range of features such as multiple analysis, regression, and clustering algorithms. We are going to write a simple program to demonstrate how supervised learning works using the Sklearn library and the Python language.
Sklearn also interoperates well with the NumPy and SciPy libraries.
Install Sklearn
The Sklearn installation guide offers a very simple way of installing it for multiple platforms. It requires several dependencies:
- Python (>= 3.6),
- NumPy (min version 1.17.3)
- SciPy (Min version 1.3.2)
If you already have these dependencies, you can install Sklearn as simply as:
1 |
pip install -U scikit-learn |
An easier way is to simply install Anaconda. This takes care of all the dependencies, so you don’t have to worry about installing them one by one.
To test if Sklearn is running properly, simply import it from a Python interpreter as follows:
1 |
Python 3.9.12 (main, Apr 5 2022, 06:56:58) |
2 |
[GCC 7.5.0] :: Anaconda, Inc. on linux
|
3 |
Type "help", "copyright", "credits" or "license" for more information. |
4 |
>>> import sklearn
|
5 |
>>>
|
If no error occurs, then you are good to go.
Now that we are done with the installation, let’s get back to our problem. We want to be able to differentiate between different animals. So we will design an algorithm that can tell specifically whether a given animal is either a horse or a chicken.
We first need to collect some sample data from each type of animal. Some sample data is shown in the table below.
| Height (inches) | Weight (kg) | Temperature (Celsius) | Label |
|---|---|---|---|
| 7 | 0.6 | 40 | Chicken (0) |
| 7 | 0.6 | 41 | Chicken (0) |
| 37 | 0.8 | 37 | Horse (1) |
| 37 | 0.8 | 38 | Horse (1) |
The sample data we have obtained gives some of the common features of the two animals and data from two of the animals. The larger the sample data, the more accurate and less biased the results will be.
With this type of data, we can code an algorithm and train it to recognize an animal based on the trained values and classify it either as a horse or a chicken. Now we will go ahead and write the algorithm that will get the job done.
First, import the tree module from Sklearn.
1 |
from sklearn import tree |
Define the features you want to use to classify the animals.
1 |
features = [[7, 0.6, 40], [7, 0.6, 41], [37, 600, 37], [37, 600, 38]] |
Define the output each classifier will give. A chicken will be represented by 0, while a horse will be represented by 1.
1 |
#labels = [chicken, chicken, horse, horse]
|
2 |
|
3 |
# we use 0 to represent a chicken and 1 to represent a horse
|
4 |
|
5 |
labels = [0, 0, 1, 1] |
We then define the classifier which will be based on a decision tree.
1 |
classifier = tree.DecisionTreeClassifier() |
Feed or fit your data to the classifier.
1 |
classifier.fit(features, labels) |
The complete code for the algorithm is shown below.
1 |
from sklearn import tree |
2 |
features = [[7, 0.6, 40], [7, 0.6, 41], [37, 600, 37], [37, 600, 38]] |
3 |
#labels = [chicken, chicken, horse, horse]
|
4 |
labels = [0, 0, 1, 1] |
5 |
classif = tree.DecisionTreeClassifier() |
6 |
classif.fit(features, labels) |
We can now predict a given set of data. Here’s how to predict an animal with a height of 7 inches, a weight of 0.6 kg, and a temperature of 41:
1 |
from sklearn import tree |
2 |
features = [[7, 0.6, 40], [7, 0.6, 41], [37, 600, 37], [37, 600, 38]] |
3 |
|
4 |
#labels = [chicken, chicken, horse, horse]
|
5 |
labels = [0, 0, 1, 1] |
6 |
classif = tree.DecisionTreeClassifier() |
7 |
classif.fit(features, labels) |
8 |
print(classif.predict([[7, 0.6, 41]])) |
Here’s how to predict an animal with a height of 38 inches, a weight of 600 kg, and a temperature of 37.5:
1 |
from sklearn import tree |
2 |
features = [[7, 0.6, 40], [7, 0.6, 41], [37, 600, 37], [37, 600, 38]] |
3 |
#labels = [chicken, chicken, horse, horse]
|
4 |
labels = [0, 0, 1, 1] |
5 |
classif = tree.DecisionTreeClassifier() |
6 |
classif.fit(features, labels) |
7 |
print(classif.predict([[38, 600, 37.5]])) |
8 |
# output
|
9 |
# [1] or a Horse
|
As you can see above, you have trained the algorithm to learn all the features and names of the animals, and the knowledge of this data is used for testing new animals.
Linear Regression on Large Datasets
In the second example, we will use a much larger dataset to perform Linear regression.
According to Wikipedia:
In statistics, linear regression is a linear approach for modelling the relationship between a scalar response and one or more explanatory variables (also known as dependent and independent variables).
The dataset can be found here. Download the csv file into your working directory
Let’s start by importing the necessary dependencies.
1 |
import pandas as pd |
2 |
import matplotlib.pyplot as plt |
3 |
import numpy as np |
4 |
from sklearn.linear_model import LinearRegression |
Next, load the csv data in to a pandas dataframe.
1 |
df = pd.read_csv('gdp.csv') |
To see the data’s appearance, you can use the DataFrame’s head () to see the first five rows and DataFrame’s describe () function.
1 |
print(df.describe()) |
2 |
print(df.head()) |
Here is the output:
1 |
year GDP |
2 |
count 11507.000000 1.150700e+04 |
3 |
mean 1991.265230 1.005972e+12 |
4 |
std 15.886648 4.533056e+12 |
5 |
min 1960.000000 8.824448e+06 |
6 |
25% 1978.000000 2.056874e+09 |
7 |
50% 1993.000000 1.436880e+10 |
8 |
75% 2005.000000 1.796394e+11 |
9 |
max 2016.000000 7.904923e+13 |
10 |
country Code year GDP |
11 |
0 Arab World ARB 1968 2.576068e+10 |
12 |
1 Arab World ARB 1969 2.843420e+10 |
13 |
2 Arab World ARB 1970 3.138550e+10 |
14 |
3 Arab World ARB 1971 3.642691e+10 |
15 |
4 Arab World ARB 1972 4.331606e+10 |
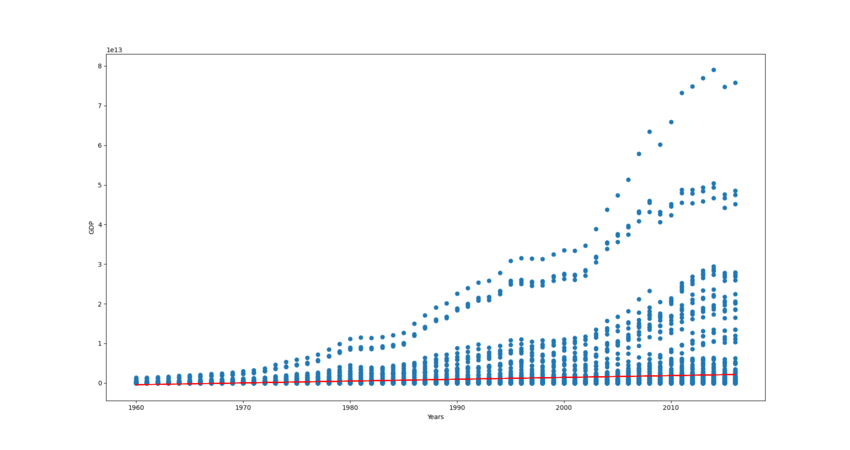
As you can see above, the data contains the GDP of different countries from 1960 to 2016. The next step is to create the x and y-dimensional arrays.
1 |
X = df['year'].values.reshape(-1, 1) |
2 |
y = df['GDP'].values.reshape(-1, 1) |
Next, create a regression model and a prediction using the X (year) as the input.
1 |
model = LinearRegression() |
2 |
model.fit(X, y) |
3 |
|
4 |
|
5 |
predictions = model.predict(X) |
Finally, plot the data and a line representing the prediction model.
1 |
plt.scatter(X, y) |
2 |
plt.plot(X, predictions, color='red') |
3 |
plt.show() |
Here is the plot:
Unsupervised Learning
Unsupervised learning is when you train your machine with only a set of inputs. The machine will then be able to find a relationship between the input data and any other you might want to predict. Unlike in supervised learning, where you present a machine with some data to train on, unsupervised learning is meant to make the computer find patterns or relationships between different datasets.
Unsupervised learning can be further subdivided into:
Clustering
Clustering means grouping data inherently. For example, you can classify the shopping habits of consumers and use the data for advertising by targeting consumers based on their purchases and shopping habits.
Association
Association is where you identify rules that describe large sets of data. This type of learning can be applicable in associating books based on author or category, whether motivational, fictional, or educational books.
Some of the popular unsupervised learning algorithms include:
- k-means clustering
- hierarchical clustering
Conclusion
I hope this tutorial has helped you get started with machine learning. This is just an introduction—machine learning has a lot to cover, and this is just a fraction of what machine learning can do. Sklearn is just one of the libraries used in machine learning. Other libraries include tensorflow and keras.
Additionally, don’t hesitate to see what we have available for sale and for study on Envato Market.
Your decision to use either a supervised or unsupervised machine learning algorithm will depend on various factors, such as the structure and size of the data.
Machine learning can be applied in almost all areas of our lives, e.g. in fraud prevention, personalizing news feeds on social media sites to fit users’ preferences, email and malware filtering, weather predictions, and even in the e-commerce sector to predict consumer shopping habits.